서버비용을 80%절감한 이벤트 기반 구조 리팩토링 개발기
이 내용은 매일 1억건씩 변경되는 상품 DB, 칼럼기반 DBMS 마이그레이션 개발기에서 이어지는 작업을 담은 내용입니다.
리팩토링의 시작
DB 마이그레이션을 통해 Replication delay 이슈를 해결했지만, 아직 EP 시스템에는 해결되지 못한 요구사항들이 존재했습니다.
1. 데이터의 역정규화
이전 DB 마이그레이션 프로젝트는 최대한 빠르게 DBMS를 교체하는 목적으로, 관계형 테이블 구조를 포함한 기존 시스템 로직을 최대한 그대로 사용하였습니다.
이로인해 기존의 정규화된 테이블을 그대로 사용 하게되어, 칼럼기반 DB인 Vertica에서는 성능상 불리한 테이블 구조를 가지고 있었습니다.
2. 변경 상품 체크를 위한 Redis와 DB간의 상품 정보 비일치 문제 해결
수집한 EP 상품의 변경여부를 빠르게 체크하기 위해 상품 데이터를 Redis에 를 두고 상품정보를 저장하여 사용하였으나,
캐시로 사용된 것이 아닌 Persistent data가 저장된 Redis와 DB 간에 데이터 불일치가 발생하면서 비정상적인 변경상품체크가 일어나는 현상이 간간히 발생했습니다.
3. 서버의 비효율적인 사용
서버가 항시 수행중이 아님에도 많은 EC2 인스턴스가 상시 운영중인 상황 이었습니다.
특히 1일 1회 수행되는 크롤링서버, 이미지 변경내용이 있을때만 수행되는 이미지 수집서버들이 비효율적으로 인스턴스를 사용중 이었습니다.
4. 이미지 수집서버의 비균등한 작업 할당 문제 해결
이미지 작업 부하 분산을 위해 상품의 해시 ID 기반으로 인스턴스들이 작업이 작업을 분배하여 할당받고 있었습니다.
상품 ID가 해시를 통해 균등하게 생성된다는 특성을 가졌기때문에 ID 앞자리를 특정하여 인스턴스별로 작업 Slot을 할당하여 부하를 분산시키고 있었습니다. |인스턴스|상품ID| |:–:|:–:| |server1|00~0F| |server2|10~1F| |server3|20~2F| |…|| |server16|F0~FF|
이는 부하 분산을 위한 목적이었지만, 실제로는 특정 ID Slot에 작업이 몰려서 들어오거나 작업이 지연되는경우 작업 적절하게 분배되지 않는다는 문제가 확인되었습니다.
상품 ID가 해시를 통해 균등하게 생성된다는 특성을 가졌기때문에 ID 앞자리를 특정하여 인스턴스별로 작업 Slot을 할당하여 부하를 분산시키고 있었습니다. |인스턴스|상품ID|작업대기상품| |:–:|:–:|:–:| |server1|00~0F|001111, 0A0211, 055AA1, 073A21| |server2|10~1F|101111| |server3|20~2F|27F00A(작업 지연), 203AA1, 275001, 2AAFFF, 2445A1 …| |…||| |server16|F0~FF||
EP 수집 로직의 변경
1,2번 요구사항을 해결하고자 EP 수집 로직을 변경하였습니다.
기존 EP 수집로직 )
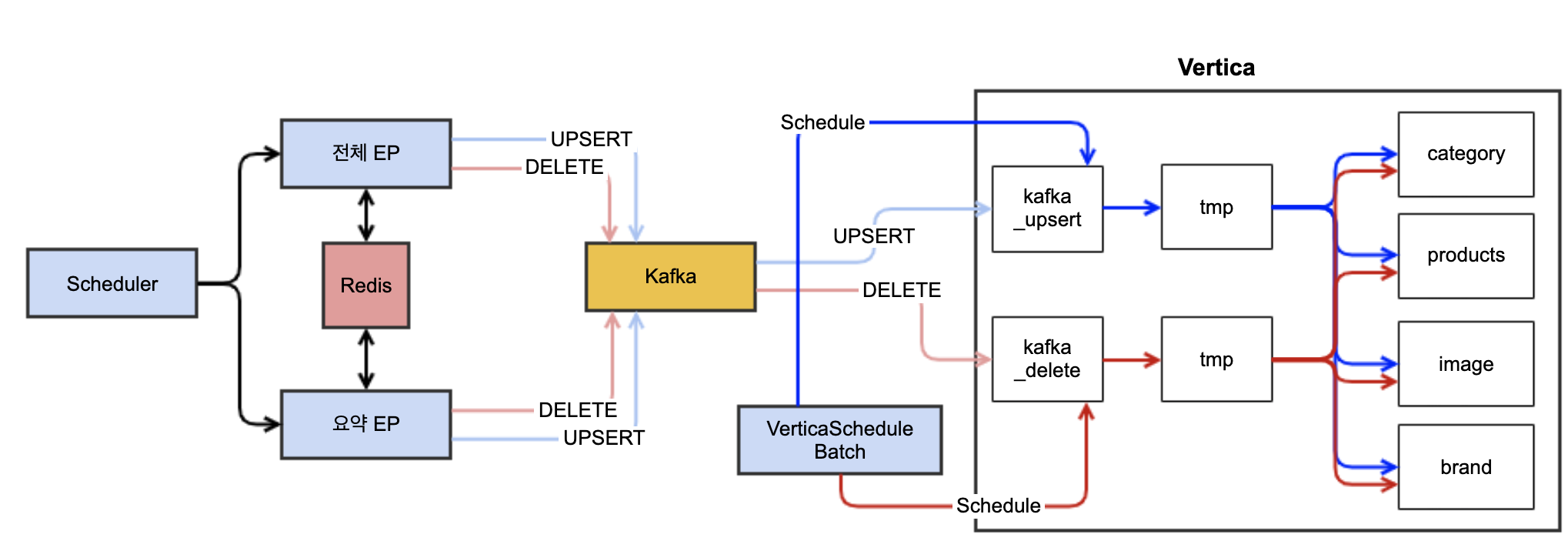
- 이슈 1) 데이터 정규화 문제
- 이슈 2) Redis ↔ DB 간의 상품 비일치 문제
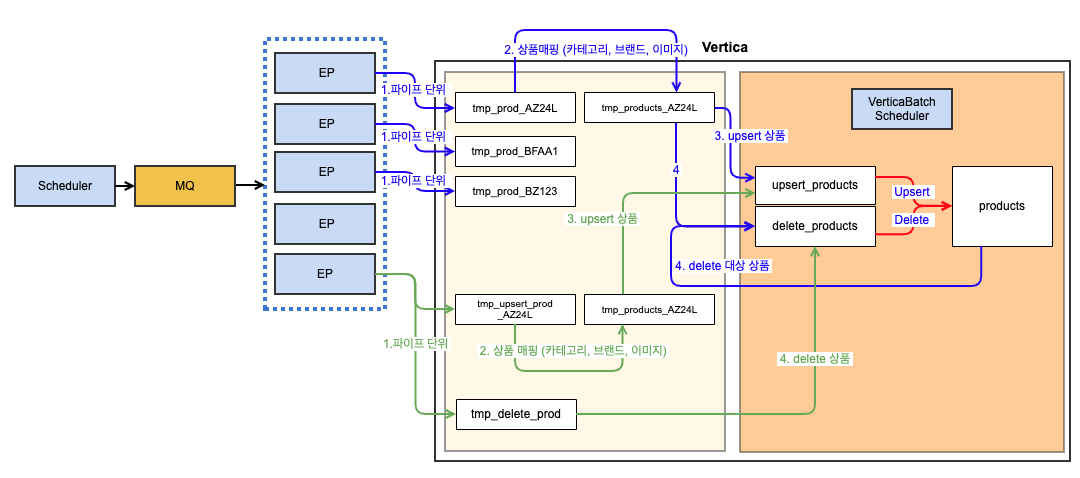
-
칼럼기반 DB 친화적 데이터 구성 → 정규화 되어있던 상품 정보들(상품, 카테고리, 브랜드, 이미지)을 역정규화 한 하나의 테이블 구축
-
DB 내부에서 상품 변경여부 검증 → 대량 데이터 처리에 강점을 가진 Vertica DB를 사용해 상품 변경여부를 DB에서 직접 판단 → Redis 제거
-
제휴 몰(파이프)단위로 수행로직 변경 → 대량 데이터 처리에 이점을 가진 Vertica를 잘 활용하고자 ‘상품단위’ 프로세싱이 아닌 ‘파이프’단위 프로세싱으로 변경 → 상품 변경 여부 검증, 상품 정보 매핑 모두 파이프단위로 진행 → 파이프 단위로 작업 진행하여 작업 병렬성 높임
-
Kafka 제거 → 파이프 단위 순차처리를 위해 기존
상품단위프로세싱에서 사용되던 Kafka 미사용 → Bulk-load에 강점을 가진 Vertica DB를 통해 서버에서 직접 데이터 로드 → 관리포인트 줄어듬 (Kafka, Consumer)
EP 수집 시스템 구성의 변경
3번 요구사항을 해결하기위해 서버의 효율적인 사용에 대해 개선 여지가 있었던 레거시 EP 수집 시스템 아키텍쳐를 리팩토링 하기로 결정하였습니다.
기존 시스템 아키텍쳐 )
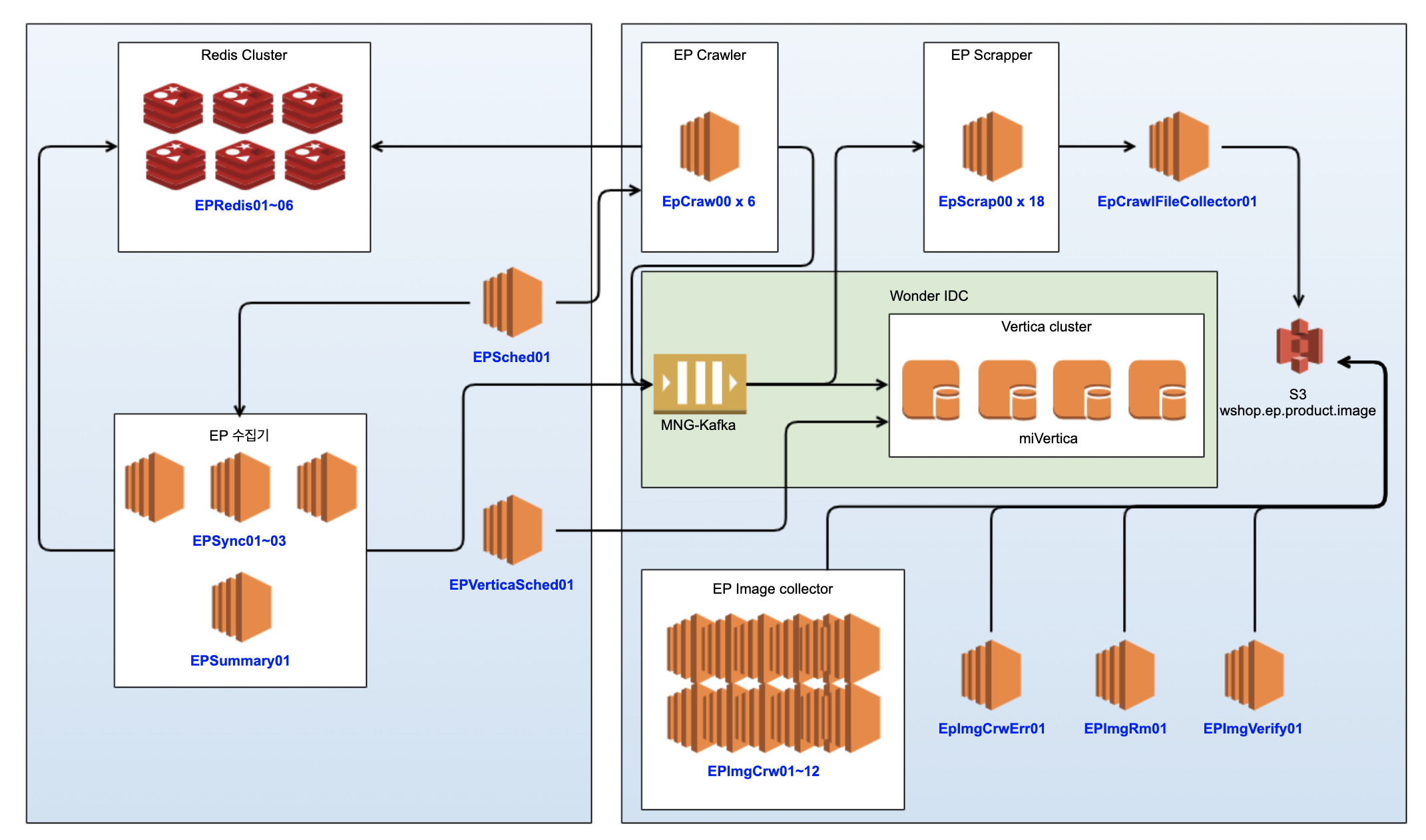
-
이슈 1) EPCraw, EPScrap 서버의 비효율적인 서버 사용 제휴된 업체의 웹사이트에 접속해 직접 상품 크롤링 작업을 담당하는 서버로써, 1일 1회 수행되지만 일시적인 부하 분산을 위해 많은 서버들이 상시로 운영중
-
이슈 2) EPImgCrw 서버의 비효율적인 서버 사용 제휴 상품의 이미지를 다운받아 자체 S3에 저장하는 서버로써, 변경 상품이 많이 없을때에도 많은 서버들이 상시로 운영중
-
이슈 3) EpImgCrw 서버의 비균등한 작업 분산 할당
변경 시스템 아키텍쳐 )
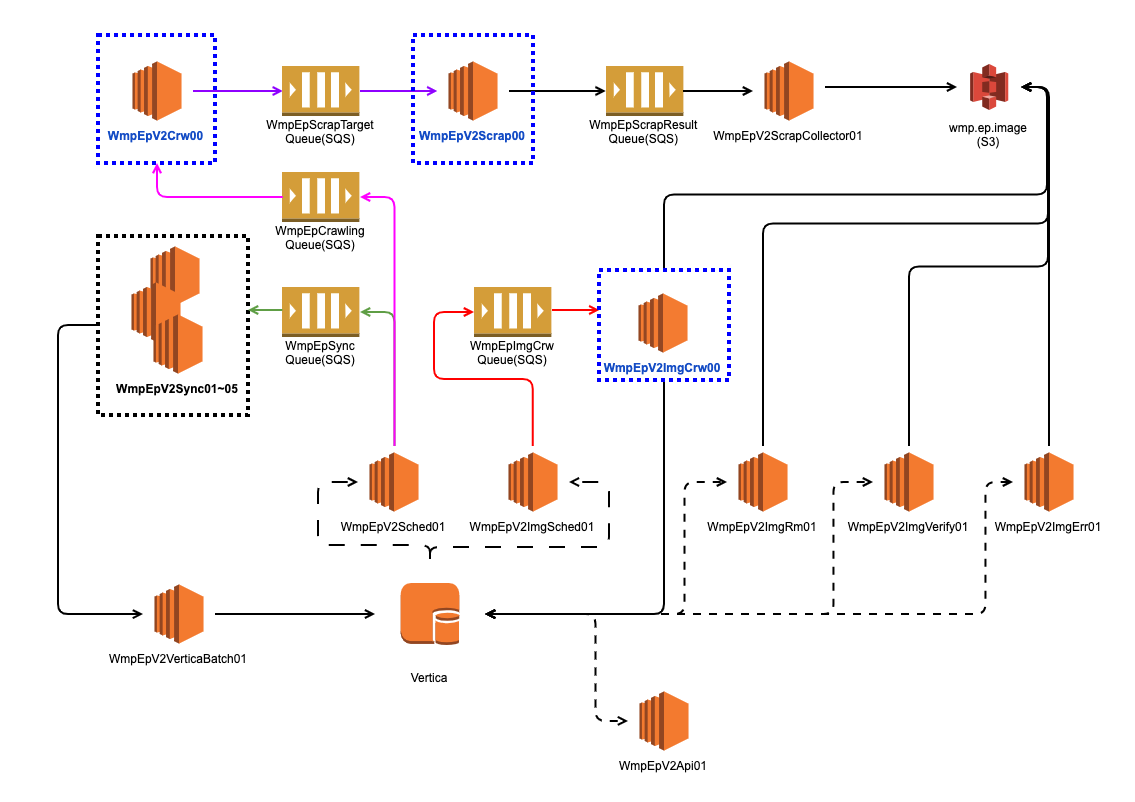
-
이벤트 발생량에 따른 동적 서버 할당 → 비효율적으로 사용되던 EpCrw, EpScrap, EpImgCrw 서버들을 이벤트 발생량에 따라 인스턴스가 동적으로 추가 될 수 있도록 변경 → SQS + CloudWatch + SpotInstance + Autoscaling
-
큐(SQS)를 사용한 이벤트 전달 → 서비스 직접 호출이 아닌 큐를 통해 이벤트를 전달하여 Producer, Consumer 간의 결합도 낮춤 → 큐를 통한 이벤트 균등분배
최종 프로젝트 목표 설정
위의 변경내용을 종합해보면, 최종적으로 이번 리팩토링 프로젝트의 목표는 아래와 같이 세워졌습니다.
- EP 역정규화
- Kafka 제거 → 관리 포인트 감소 및 통신 딜레이 감소
- Redis 제거 → EP 상품 정합성 확보 (Redis, DB 상품 캐시로 인한 불일치 문제 해결)
- Queue를 통한 작업 분배 → EP 시스템의 효율적 사용
- SQS + Autoscaling + Spot-instance 사용 → 효율적인 오토스케일링 정책으로 인스턴스 비용 절감
트러블 슈팅
SQS
저희가 일반적으로 사용하는 메세지 시스템인 Kafka를 사용하지않고 SQS를 사용한 이유는 Cloudwatch-Autoscaling 연동이 간편하게 잘 되기 때문이었습니다.
그러나 저희팀에서 SQS사용 경험이 없어, 초기에는 SQS의 특별한 정책으로 인해 몇가지 이슈를 직면하기도 했습니다.
한가지 이슈로 [EP 스케쥴러 → SQS → EP 수집기] 구간에서 큐에 메세지가 정상적으로 쌓이는것이 확인 되지만, 여러대로 구성되어있는 EP 수집기에서 동일한 파이프를 반복해서 수집하는 현상이 발견되었습니다.
가장먼저 조치한 방법은 SQS를 기존 표준대기열 큐 에서 FIFO 큐으로 변경한 것입니다.
SQS에는 ‘표준대기열 큐’와 , ‘FIFO 큐’ 두가지를 제공하는데 표준대기열 큐의 경우 메세지가 중복처리 될 수 있습니다.
(관련한 자세한 내용 : https://docs.aws.amazon.com/ko_kr/AWSSimpleQueueService/latest/SQSDeveloperGuide/standard-queues.html)
하지만 조치 이후에도 동일한 파이프를 반복수집하는 현상에 발생하여 원인파악 결과, SQS는 기본적으로 30초 이내에 완료처리 되지 않은(visibility) 메세지를 비정상적으로 소모된것으로 판단하여 해당 메세지를 다시금 처리 할 수 있도록 하기때문에 동일한 파이프의 중복 수집이 발생 했던 것 이었습니다.
작업 완료 시간이 오래걸릴수 있는 EP 수집 프로세스 특성상 위 이슈는 SQS의 정책상 당연하게 에러로 판단될수 있는 로직이라, EP 수집기에서 visibility-time을 직접 조작하여 해결 할 수 있었습니다.
Vertica DB 대용량 역정규화 테이블 데이터 merge
칼럼기반 DB 특성상 정규화되지 않은 테이블이 더 좋은 성능을 낸다고 말씀 드렸으나, 이는 어디까지나 조회성능이 이야기입니다.
상품 테이블을 역정규화하면서 해당 테이블의 칼럼은 101개가 되었습니다.

Insert는 큰 문제 없지만, Update의 성능을 간과하였습니다.
변경된 상품 데이터를 반영하기 위해 Merge (upsert) 하는경우 3,000만건 수행시 2시간 이상 수행되는 현상이 발생하였습니다.
이는 기존 성능의 2배 이상 느려진 속도로써, 테이블락이 걸리는 Vertica 특성상 절대 용인될 수 없는 수행로직 이었습니다.
다행히도 이 문제는 Merge 구문 사용 대신, Delete + Insert 로직으로 변경하여 간단하게 해결 할 수 있었습니다. (CDC를 사용하지 않는다는 전제…)
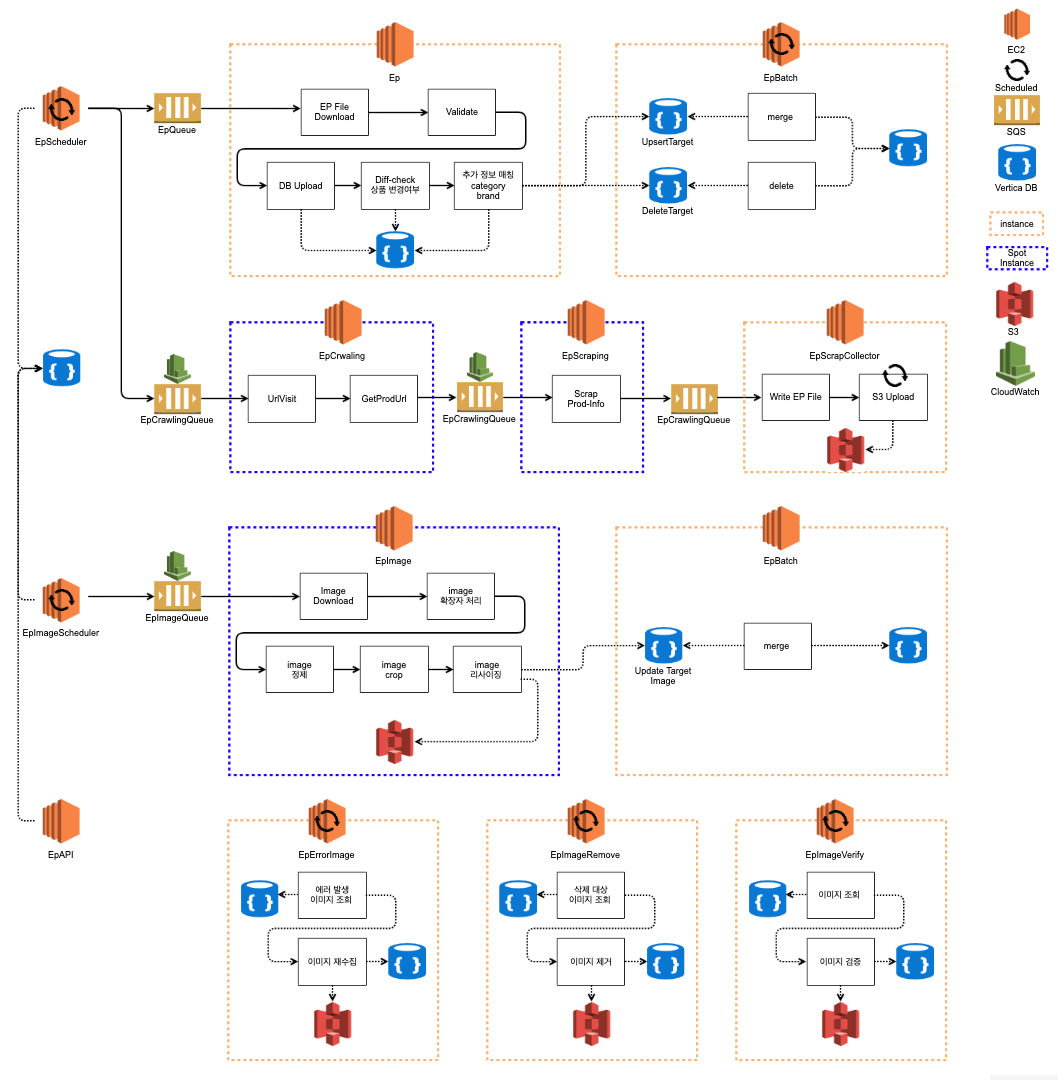
최종 서비스 플로우
시작은 ‘리팩토링’ 프로젝트였지만, 사실은 위 변경사항들을 구현하기위해 기존 코드를 사용하는것보다는 새로 만드는것이 더 낫다고 판단하여 EP 시스템의 모든 프로젝트를 새로 만드는 ‘리빌딩’을 진행하였습니다.
그럼에도, 이전 DB 마이그레이션 프로젝트에서 Vertica DB를 쓴맛을 맛보면서 친해진 탓인지 빠르고 수월하게 작업을 진행 할 수 있었습니다.
최종적으로 구축된 전체 서비스 플로우는 아래 다이어그램과 같습니다.
최종 프로젝트 결과
최종적으로 이 프로젝트에서 아래와 같은 성과를 도출 할 수 있었습니다.
전체 서버 비용 약 80% 이상 절감- 관리 포인트 절감 (Redis, Kafka 제거)
- 스팟인스턴스 사용 (온디맨드 인스턴스에 비해 약 50% 저렴)
- 이벤트 발생량에 따른 동적 서버 할당 (SQS + CloudWatch + SpotInstance + Autoscaling)
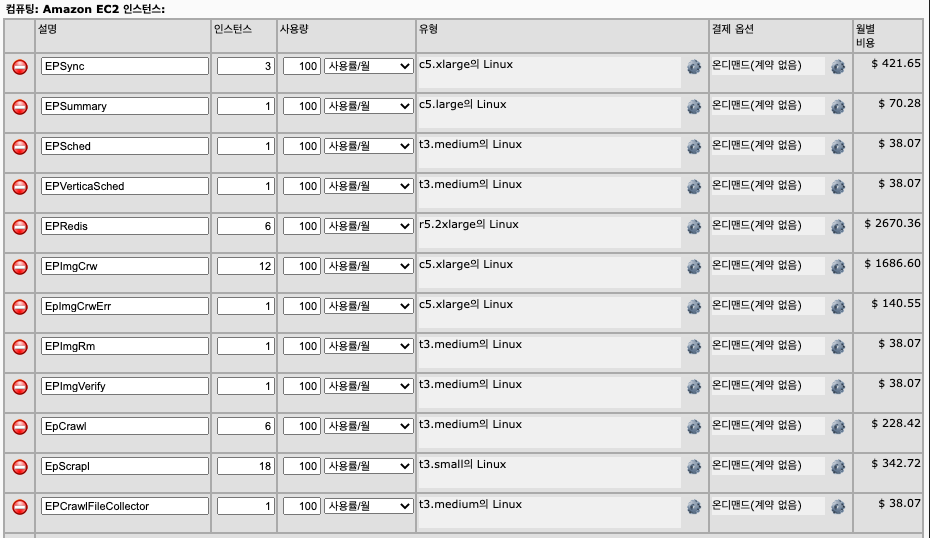
기존 EC2 비용 계산기
- 월 $5750.93 (약 6,400,000원) → 연 76,800,000원
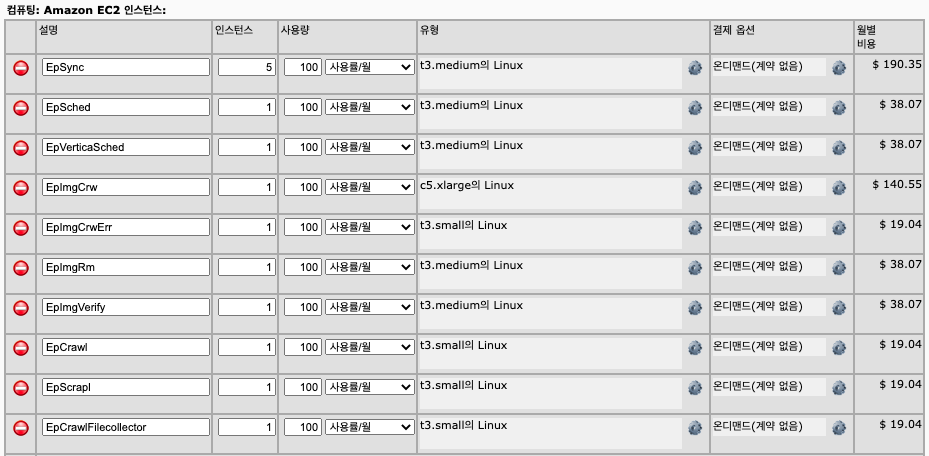
리팩토링 이후 EC2 비용 계산기
- 월 $559.34 (약 620,000원) → 연 7,440,000원 (위 금액은 On-demand instance 금액입니다.)
- + 이벤트 발생량에 따라 Spot instance 금액 (On-demand의 50% 비용)
- + SQS 사용량에 따른 금액
(Kafka는 사내 공용 Kafka를 사용했기에 요금 계산에 포함되지 않았습니다.)
검색 색인 조회 쿼리 속도 10배 이상 향상 확인- 전체 색인 쿼리 limit 1000(3.3s → 200ms)
- 증분 색인 쿼리 limit 1000(4.5s → 200ms)
- MQ를 통한 효율적인 작업 분배 시스템 구축
- 일반 상품 조회 속도 약 10%의 향상 확인
후기
사실 해당 프로젝트를 시작할때에는 성능및 효율성개선을 목표로 진행한 프로젝트였는데, 최종 결과로는 비용적 측면에서 큰 개선을 얻을수 있었던 작업이었습니다.
지난 마이그레이션 작업에서 Vertica에 대해 미숙했던점을 보완할 수 있었고, 앞으로 더 많은 데이터가 들어오더라도 효율적으로 서비스 할 수 있는 시스템을 구축했다는것에 만족스러운 결과를 얻은 작업이었다고 생각합니다.