매일 1억건씩 변경되는 상품 DB, 칼럼기반 DBMS 마이그레이션 개발기
시작에 앞서…
마이그레이션 경험기를 말씀드리기전에 우선, 마이그레이션 대상인 EP 상품DB에 대한 간략한 설명부터 드리도록 하겠습니다.
EP 상품은 위메프에서 자체적으로 판매하는 상품이 아닌 외부 제휴업체로부터 전달받는 상품이며, 위메프 모바일 앱에서 “제휴쇼핑몰 추천상품”에 노출되는 상품입니다.
(위메프 모바일앱에서 아래와 같이 노출되는 상품들입니다.)
현재 위메프에서 제공하는 제휴업체 상품은 약 3억건 정도인데,
제휴 업체별로 정해진 시간에 판매중인 상품정보 (이하 “EP 상품”) 들을 수집하고 있습니다.
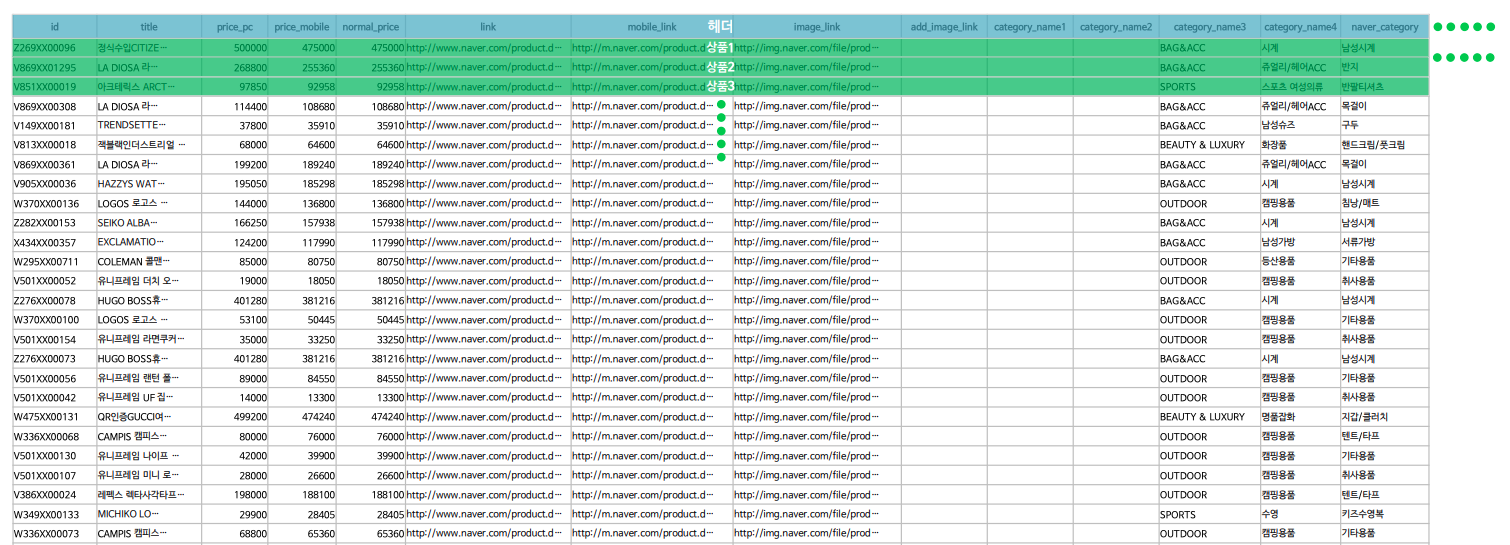
일반적으로 EP 파일은 아래 샘플 사진과같이 수집됩니다.
마이그레이션의 시작
EP 상품 시스템 초기구축으로 부터 3년이 지난 지금, 예상 허용치였던 1~2억건을 이미 넘어섰고 위메프 카탈로그가 도입되면서 EP 상품 데이터 확장 계획을 가지고 있던 상황에서 아래와 같은 이슈들이 확인되었습니다.
Replication delay
기존 MySQL의 경우 부하 분산 및 HA를 위해 Replication을 통해 Master - Slave DB를 구축하여 사용중입니다.
EP 상품의 특성상 직접관리하는 자체 상품과는 다르게, 잦은 업데이트가 발생해 어쩔수 없이 Replication delay 현상이 발생하고 있었습니다.
특히나 명절 및 이벤트를 앞둔 날 이면 많은 상품들에 변경이 일어나면서 최대 8시간의 Replication 동기화 지연이 발생 하였습니다.
명절 상품 변경 예시 )
비스포크 냉장고 → [한가위 특가] 비스포크 냉장고
롯데 빼빼로 → [빼빼로데이] 롯데 빼빼로
…
초기 구축 이후 트래픽 증가에 따라 DB 스케일업을 진행 했지만 이미 클라우드에서 제공하는 최고 스펙의 인스턴스를 사용중 이었기 때문에 비용과 확장성을 고려하여 시스템의 변경이 불가피 하였습니다.
어떻게 문제 해결을 할 것인가
이 문제들을 해결하기 위해 고사양 스펙을 가진 IDC를 구축하는 방안도 있었겠지만 가장 큰 문제라고 여겨졌던 Replication 동기화 지연문제를 원초적으로 해결 하기 위해 분산 DB를 도입하는쪽으로 결정이 되었습니다.
그 중 후보로 나온 DBMS들은 아래와 같습니다.
- HBASE
- Cassandra
- Vertica
- …
위 후보들 모두 유명하고 검증된 분산형 DBMS 들 이지만, 대규모 마이그레이션 진행에 직접적으로 도움 받을 수 있는 상용 DBMS인 Vertica를 최종적으로 선택하여 진행하기로 결정 되었습니다.
칼럼 기반 (Column-oriented) DBMS
사용하기로 결정된 Vertica는 일반적으로 사용하던 로우 기반 (Row-oriented) DBMS가 아닌 칼럼 기반 (Column-oriented) DBMS이기 때문에
팀원들 모두 접해본적이 없어 우선적으로 칼럼 기반 DBMS의 특성 파악이 필요했습니다.
간단한 정리를 위해 아래와 같은 데이터 테이블이 있다고 가정해보겠습니다.
| seq | name | tel |
|---|---|---|
| 101 | 김하나 | 010-1111-1111 |
| 102 | 이둘 | 010-2222-2222 |
| 103 | 석삼 | 010-3333-3333 |
로우 기반 DBMS의 경우 아래와 같이 '행'의 단위로 데이터가 저장됩니다.
data 101;김하나;010-1111-1111,102;이둘;010-2222-2222;석삼;010-3333-3333
칼럼 기반 DBMS의 경우 아래와 같이 '열'의 단위로 데이터가 저장됩니다.
data1001:101,002:102, 003:103
data2 001:김하나, 002:이둘, 003:석삼
data3 001:010-1111-1111, 002:010-2222-2222, 003:010-3333-3333
칼럼 기반으로 데이터를 저장함으로써, 대용량 데이터에서 특정 칼럼들만 조회하는데에 유리한 성능을 낼수 있는 구조로 만들기위해 설계되었습니다.
특히나 유사한 데이터가 반복될 확률이 높은 '열' 데이터들의 경우 중복 데이터들을 압축함으로써 디스크 점유 공간을 줄이고 데이터 조회에 유리한 효과를 얻을 수 있습니다.
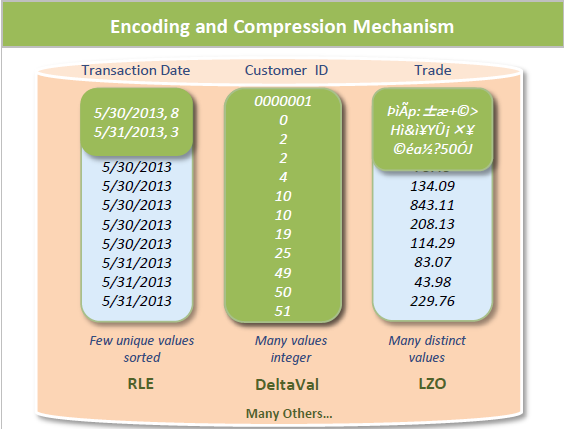
정리해보자면 칼럼 기반의 DBMS는 다음과 같은 특징이 있습니다.
- 데이터가
'칼럼'기반으로 나누어져 저장되기 때문에 테이블이 비정규화 되어있을때 더 좋은 성능을 발휘합니다. - 일반적으로 SELECT 작업은 빠를 수 있지만, UPDATE/DELETE 작업의 경우 로우 기반 DBMS에 비해 비교적 느릴 수 있습니다.
- 대용량 데이터 처리를 전제로 하기때문에 하나의 쿼리를 여러 태스크로 나누어 병렬처리를 수행합니다.
위와 같은 특성들로 인해 칼럼 기반 DBMS는 OLAP (OnLine Analytical Processing) 처리에 특화되어 있습니다.
사실 저희가 마이그레이션하는 서비스가 OLAP성의 서비스라 판단하기는 어렵지만, Vertica 사용시 아래와 같은 이점들을 얻을 수 있을것이라 판단 하였습니다.
- 데이터 샤딩을 통해 Replication 동기화 지연 없는 Read/Write
- 대용량 데이터 조회 성능 향상
- 대용량 데이터 갱신 성능 향상
POC 테스트
마이그레이션에 앞서서 기존 MySQL로 구성된 EP 상품 DB를 Vertica로 대체 할 수 있을지 약 한달간 POC (Proof of concept) 테스트를 수행하였습니다.
POC에서 중점적으로 테스트한 사항은 다음과 같습니다
- 4억건 EP 상품 처리시 안정적인 운영이 가능 할 것인가 (서버 부하)
- 상품 갱신의 성능 개선
- 상품 조회의 성능 개선
몇가지 테스트 결과를 공유드리자면 아래와같은 놀라운 결과가 나왔습니다.
| 테스트 | 테스트내용 | 결과 |
|---|---|---|
| test-1 | 5억건 테이블에 2천만건 Upsert 성능 측정 | 2분 22초 |
| test-2 | 5억건 테이블에 Non-pk 칼럼 조회 성능 측정 select * from product WHERE name like ('%'\|\|#{name}\|\|'%') |
0.5초 |
| test-3 | 5억건 테이블에 count(*) 성능 측정 | 0.6초 |
테스트 결과 조회 성능에 있어서 놀라운 퍼포먼스가 측정되면서 단순 대체가 아닌 업그레이드가 가능할것이라는 판단하에 MySQL → Vertica 마이그레이션은 최종 확정되었습니다.
이때까지만해도 앞으로의 마이그레이션 길은 꽃길만 펼쳐져 있을 줄 알았습니다…
EP 수집 로직의 변경
로우 기반 DBMS 인 MySQL는 OLTP (Online transaction processing) 처리에 특화된 반면 칼럼 기반 DBMS 인 Vertica는 OLAP (OnLine Analytical Processing) 처리에 특화되어 있기때문에 기존 EP 수집 로직에 많은 변경이 필요 했습니다.
우선 Vertica는 ANSI SQL를 지원하기때문에 쿼리 자체의 큰 변경은 없었습니다. (대부분의 쿼리들은 Oracle 문법으로 사용 가능합니다)
다만, 기존 MySQL에서는 Upsert 된 EP 상품들에 대해 자체 카테고리 및 브랜드 매핑 기능이 트리거와 프로시져로 구현되어 있었으나 Vertica에서는 트리거와 프로시져를 지원하지 않아 별도로 처리 할 수 있도록 로직 변경이 필요했습니다.
칼럼 기반 DBMS의 경우 사실 역정규화된 테이블에서 최고의 성능을 발휘하지만 이번 마이그레이션에서는 최대한 기존 시스템의 변화 없이 빠르게 작업하는것으로 목표했기 때문에 정규화된 테이블을 그대로 사용하였습니다.
기존 EP 수집로직 )
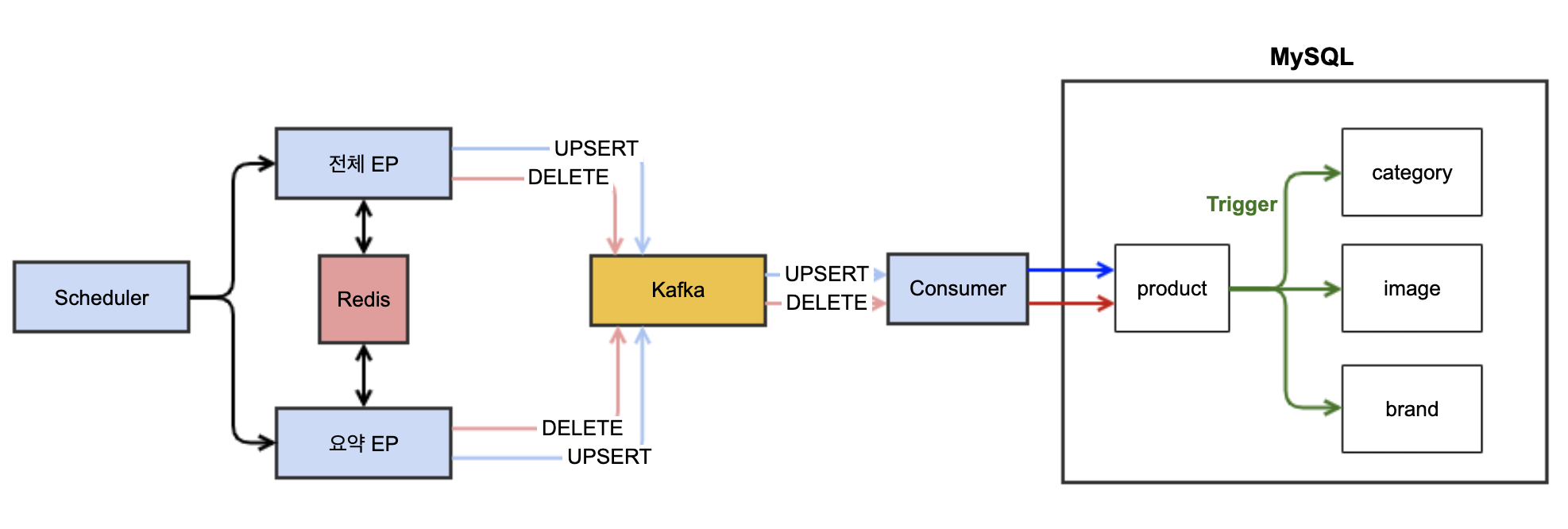
변경 EP 수집로직 )
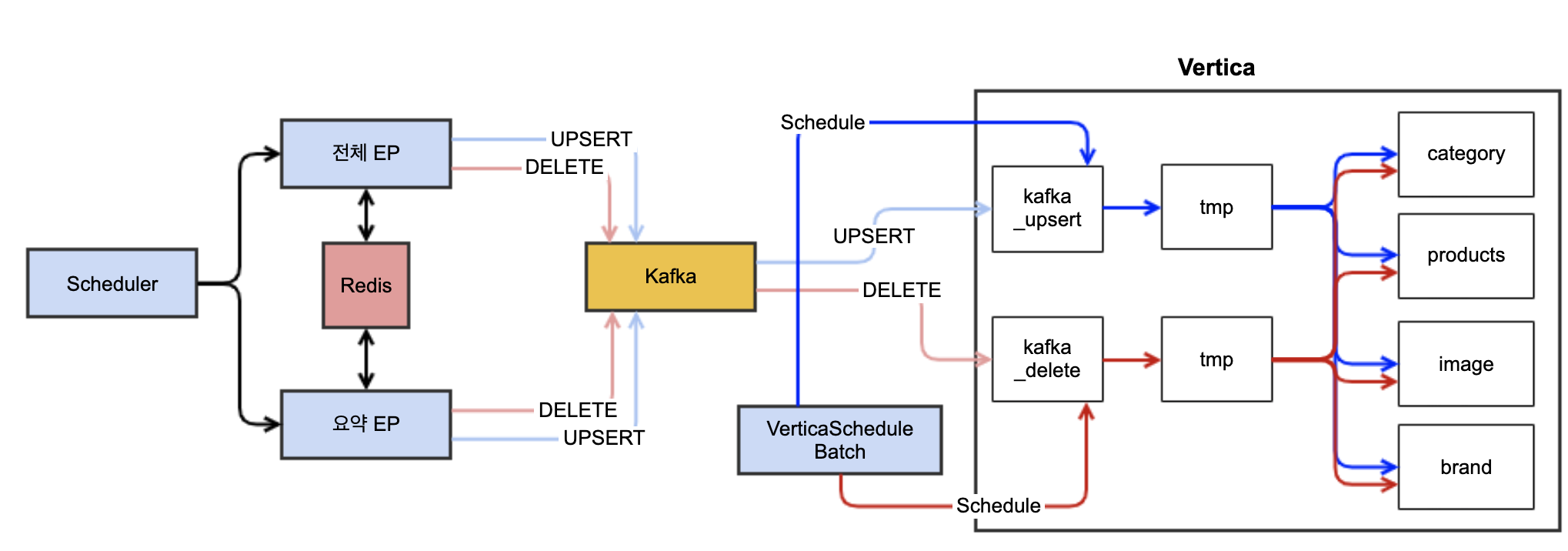
배치 처리를 통한 프로시저와 트리거 기능 대체
- Vertica add-on 을 통해 Kafka 데이터 지속적인 적재
- 배치 서버에서 fixed-delay 00분 마다 Upsert 대상 상품 00건 처리
- 배치 서버에서 fixed-delay 00분 마다 Delete 대상 상품 00건 처리
트러블 슈팅
이슈 1) 배치 처리 성능 저하
초기에는 50만건씩 Upsert를 수행하는데 1분 정도 소요가 되었으나 배치 스케쥴이 수행 할 수록 점점 느려지다가 발생하는 예상하지 못한 이슈가 발생했습니다.
해당 이슈는 Vertica에서 데이터를 처리하는 내부 자료구조의 특성에 따른 이슈였습니다.
Vertica에서는 데이터를 ‘ROS (Read Optimized column Store)’에 저장합니다.
Insert, Update 작업을 수행 할 때 마다 별도의 ROS 를 생성하고 삭제가 일어 날 때 DV(Deleted Vector)를 생성해 삭제된 데이터를 마킹해주는데 이러한 이유로 인해 ROS와 DV가 많아질 수록 조회시 참조해야할 ROS들이 많아지면서 성능이 급격하게 나빠지게 됩니다.
(update문의 경우도 내부적으로는 delete & insert로 처리되어 DV가 생성됩니다.)

위와 같은 특징 때문에 내부적으로는 Merge-out 이라는 작업을 주기적으로 수행하여 ROS를 합쳐주는 작업을 진행합니다.
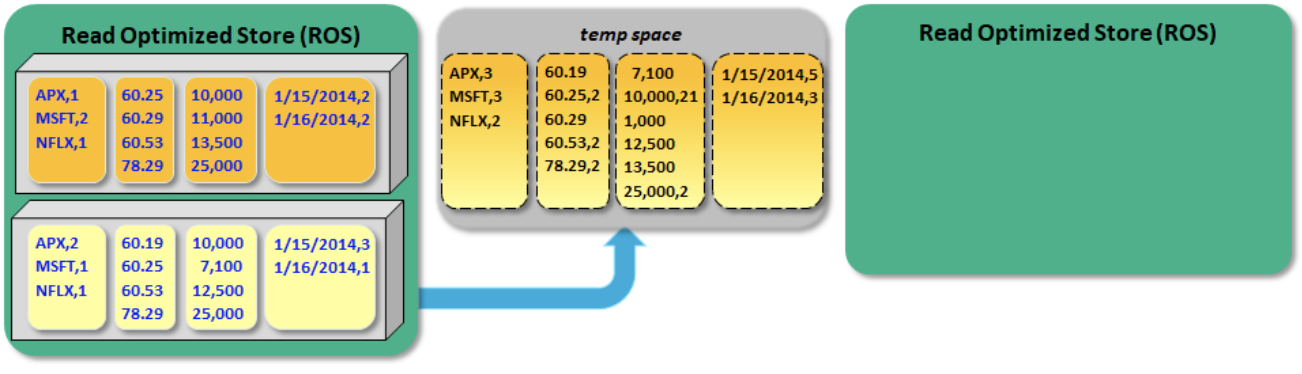
하지만 Merge-out 이 수행되는데는 데에도 꽤나 오랜시간이 걸리기때문에 결국에는 Vertica, Column-oriented DBMS를 사용하는 목적인 OLAP에 더 친화적으로 데이터를 처리해야 했습니다.
따라서 최종적으로는 한 동작에 많이 처리 할 수 있도록 스케쥴 시간을 늘리고 더-대용량 처리를 함으로써 ROS의 과도한 생성을 막았습니다.
- 배치 서버에서 fixed-delay 1분 → 10분 마다 Upsert 대상 상품 50만 → 3,000만 건 처리
- 배치 서버에서 fixed-delay 10분 마다 Delete 대상 상품 10만 → 1,000만 건 처리
‘사실 처음에는 50만건씩 처리하는것도 충분한 대용량 처리를 하는것이지않을까…’ 생각했으나 Vertica의 대용량처리는 기본적으로 ‘n천만 ~ n억대의 데이터’ 처리에 유리하다고 답변을 얻었습니다.
이슈 2) 테이블락으로 인한 Lock-wait timeout 발생
Vertica는 기본적으로 Row-lock 이 아닌 Table-lock 이 걸리게됩니다. 그도 그럴것이 위의 이슈에서 확인 했던 것 처럼 ‘대용량 데이터 처리’에 최적화된 DBMS 이기 때문에 Row-lock 이 아닌 Table-lock으로써 성능상의 이슈를 갖도록 설계되어있습니다.
처음 작업 수행시에는 적은 데이터 상품으로 개발 테스트를 하다보니 lock-wait는 발생하였지만 timeout error는 발생하지 않아 캐치를 하지 못했는데, 이슈1 에서 데이터 사이즈를 늘리면서 처리시간이 늘게되어 상품 Upsert와 Delete 간에 Lock-wait timeout이 발생하는것을 확인하였습니다.
위의 이슈를 피하기 위한 Upsert와 Delete 로직을 하나의 스케쥴로 변경하였습니다.
-배치 서버에서 fixed-delay 10분 마다 Upsert 대상 상품 처리 (완료후) → Delete 대상 상품 처리
이슈 3) CPU 과부하
메모리 사용량은 물론이고 아무래도 분산형 DB다 보니 대부분의 쿼리에서 분산 처리를 수행하기 때문에 CPU 부하가 심합니다.
이를 해결하기 위해 계정별 resource pool을 설정하고, 동시실행 가능한 쿼리 갯수를 제한해 둔다거나,
최대 CPU 사용량을 지정해 두는 등의 resource managemnet가 중요합니다.
(https://www.vertica.com/kb/BestPracticesforManagingResourcePools/Content/BestPractices/BestPracticesforManagingResourcePools.htm)
이슈 4) Read 성능 저하
처음 POC 테스트 진행시 가장 놀랐던건 엄청난 데이터 Read 성능이었습니다.
하지만 실제 데이터를 수집하면서 Read를 진행해보니 예상에 한참 못미치는 성능이 나오고 있었습니다.
원인을 파악해보니 이슈 1) 에서 ROS의 과도한 생성을 막기는 했지만, 서비스의 특성상 주기적으로 데이터 갱신이 일어나기 때문에 ROS 와 DV가 생성 될 수 밖에 없습니다.
이렇게 누적된 ROS와 DV로 인해 처음 POC 테스트에서 확인되었던것 만큼의 획기적인 Read의 성능이 나오지 않았던 것 입니다.
이 이슈를 해결하기위해 결국은 DB 내부적으로 Read 전용 테이블을 구성하여 CQRS를 구성하였습니다.
ROS, DV는 테이블에 속하는 프로젝션 단위로 생성되고 관리되어지기 때문에 잦은 변경이 일어나는 master 테이블과 분리된 read-only 테이블을 만들어 줌으로써 read 작업의 성능을 높였습니다.
물론 CQRS를 적용하면서 read 테이블의 갱신을 위한 작업이 추가되어 약간의 복제 지연 시간이 생겨났습니다.
(4시간마다 전체 데이터가 갱신되고 10분마다 변경된 상품들에 대해 증분처리를 진행하여 데이터를 갱신)
최종 프로젝트 결과
최종적으로 무중단으로 DB 마이그레이션을 진행했으며, 아래와 같은 성과를 도출 할 수 있었습니다.
| 순번 | 내용 | AS-IS | TO-BE |
|---|---|---|---|
| 1 | Replication delay | 최대 8시간 | 최대 10분(CQRS) |
| 2 | EP 수집 속도 | 4,166p /sec (Trigger 작업완료 까지) |
6,000p ~ 8,000p / sec |
이번 프로젝트의 가장 큰 목표였던 Replication delay 이슈는 분산형 DB 사용을 해결이 완료되었고, 더불어 로직이 변경되면서 EP 수집 성능도 개선된 점을 확인 할 수 있었습니다.
후기
익숙하지 않은 DBMS 를 사용한 (관련 자료도 많이 없는) 프로젝트를 진행하면서 생각치 못했던 다양한 이슈들을 많이 만났습니다.
칼럼기반 DB 자체가 친숙하지않아 우여곡절도 많고 생각만큼의 퍼포먼스도 나오지 않아 실망도 했지만 분명히 큰 장점을 가진 DBMS라고 생각합니다.
사실 해당 시스템의 구조가 OLAP 보다는 OLTP에 적합한 구조이기 때문에 많은 난관이 있었던것은 사실이고 아직 완벽하게 해결되지 않은 문제도 존재하지만 이부분은 앞으로 계속해서 개선해나갈 예정입니다.
전체적으로는 새로운 형태의 DB를 탐구해가며 다양한 시도를 해 보면서 성공적으로 미션을 완수 해 낸 즐거운 작업이었습니다.