Chunk-oriented processing
Spring batch가 제공하는 가장 큰 특징중 하나는 청크지향 프로세싱이라고 할 수 있습니다. 청크지향 프로세싱이란, 일반적으로 대용량 데이터를 처리하는 배치 프로세스의 특성상 대상 데이터들을 하나의 트랜잭션으로 처리하기에는 어려움이 있기때문에 대상 데이터를 임의의 Chunk 단위로 트랜잭션 동작을 수행하는것을 말합니다.
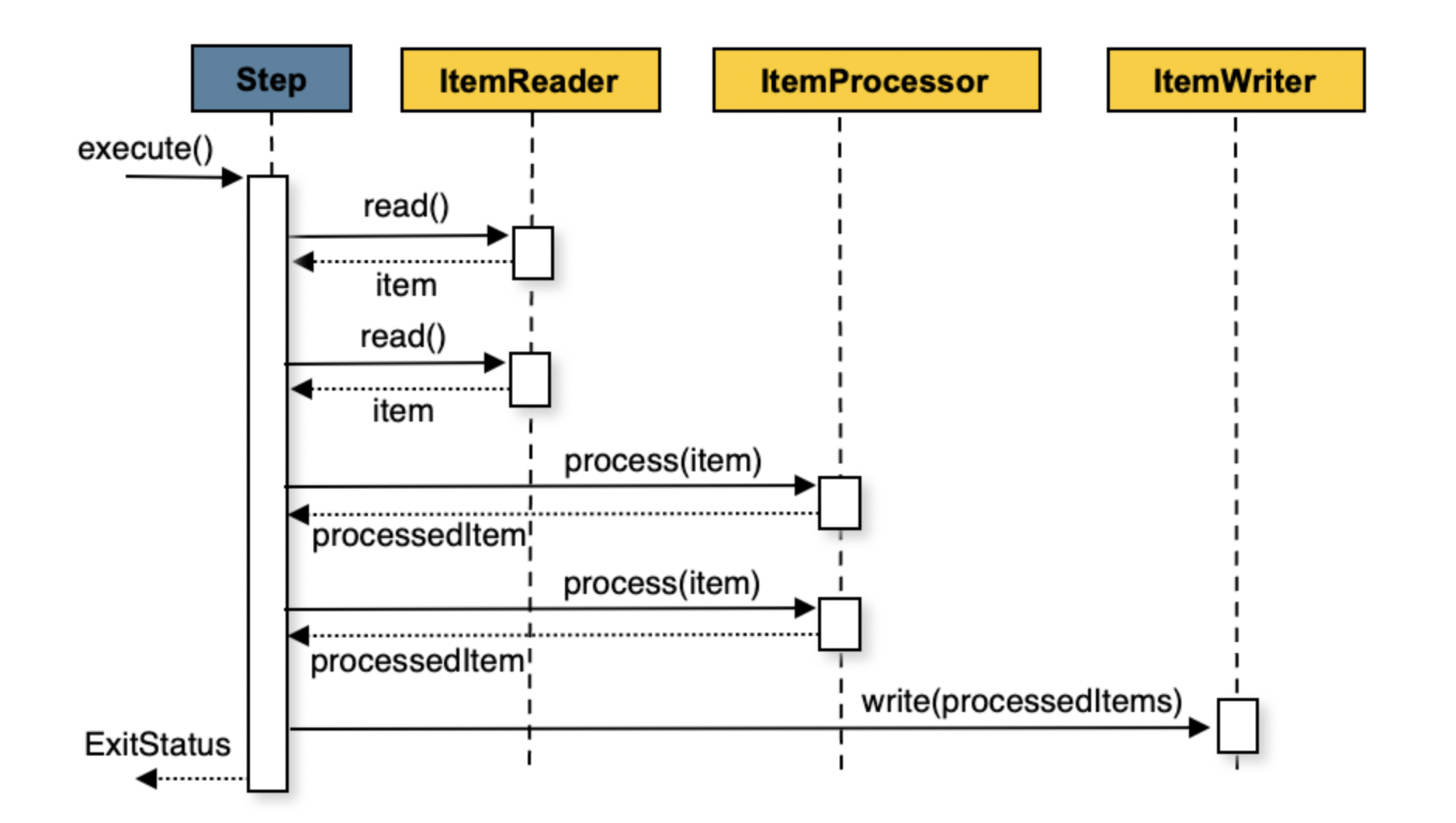
코드로 가정해 보자면, 아래와 같이 commimtInterval (chunk-size) 단위로 트랜잭션 처리가 일어난다고 볼 수 있습니다.
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read();
if (item != null) {
items.add(item);
}
}
List processedItems = new Arraylist();
for(Object item: items){
Object processedItem = itemProcessor.process(item);
if (processedItem != null) {
processedItems.add(processedItem);
}
}
itemWriter.write(processedItems);
청크지향 프로세싱은 Spring batch의 Step에서 설정이 가능하며, 위 모식도와 같이 청크지향 프로세싱은 일반적으로 ItemReader -> ItemProcessor -> ItemWriter 3단계로 이루어 집니다.
@Bean
public Job sampleJob() {
return this.jobBuilderFactory.get("sampleJob")
.start(step1())
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build();
}
위 StepConfig 코드를 통해 청크지향 처리과정을 일부 엿볼 수 있습니다.
<String, String> chunk(10)
앞에오는 String 타입은 Reader에서 반환되는 타입을 지정해주고, 뒤에오는 String 타입은 Writer에서 파라미터로 받는 타입을 지정해줍니다. 즉, 중간 Processor에서는 Reader에서 읽어들인 데이터를 가공해 형변환이 발생 할 수 있다는 뜻 입니다.
또한 chunk(10)의 의미는 청크단위를 10개로 지정하는 내용으로, 트랜잭션을 데이터 10개씩 처리한다는 의미로 해석 할 수 있습니다.
Chunk-oriented processing의 장점
위에서 알아본 청크지향 프로세싱을 사용하지 않는다 하더라도 개발자가 충분히 비슷한 로직으로 구현을 할 수도 있습니다. 하지만 청크지향 프로세싱은 단순히 청크단위의 트랜잭션만 제공해주는것은 아닙니다.
Spring batch 청크지향 프로세싱의 가장 큰 장점이라고 하면, 내결함성 (Falut tolernat)를 위한 다양한 기능들을 제공하고 있다는 것 입니다.
Skip
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(flatFileItemReader())
.writer(itemWriter())
.faultTolerant()
.skipLimit(10)
.skip(FlatFileParseException.class)
.build();
}
위 코드와같이 chunk processing을 진행하면서 특정 Exception (FlatFileParseException)에 대해 에러데이터를 스킵하고 진행 할 수 있도록 설정 해 줄 수 있습니다.
배치 처리과정중에서 단순 데이터 포맷 불일치 등의 문제로인해 발생하는 특이케이스들을 특정하여 컨트롤 할 수 있습니다.
Retry
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.retryLimit(3)
.retry(DeadlockLoserDataAccessException.class)
.build();
}
Skip 뿐만아니라, 특정 Exception (DeadlockLoserDataAccessException)에 대해서는 재시도 로직을 추가 할 수도 있습니다.
Rollback
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.noRollback(ValidationException.class)
.build();
}
기본적으로 chunk 단위 트랜잭션으로 수행되기때문에, 에러발생시 Rollback이 기본이지만 특정 에러에 대해서는 no-Rollback 정책을 수행 할 수 있습니다.
다른 장점으로는 다양한 ItemReader 지원한다는점을 들 수 있습니다. 기본적으로 데이터소스를 File, DB 등에서 처리할 수 있도록 별개의 ItemReader들이 존재하며 JDBC, JPA에서 Cursor, Paging등의 방식으로 데이터를 조회 할 수 있는 기능을 제공합니다. 이와 함께 multi-thread 처리를 위한 기능 또한 제공하고 있습니다.
무조건 Chunk-oriented processing을 써야 할까?
Chunk-oriented processing대신 TaskletStep을 사용 할 수도 있습니다.
작업로직이 청크지향 처리를 하기에는 너무 간단하거나, 부자연스러운경우 tasklet을 설정해 step을 구성 할 수 있습니다.
@Bean
public Step deleteFilesInDir() {
return this.stepBuilderFactory.get("deleteFilesInDir")
.tasklet(fileDeletingTasklet())
.build();
}
@Bean
public FileDeletingTasklet fileDeletingTasklet() {
FileDeletingTasklet tasklet = new FileDeletingTasklet();
tasklet.setDirectoryResource(new FileSystemResource("target/test-outputs/test-dir"));
return tasklet;
}
배치작업이 단순한 쿼리 수행 혹은 DB 프로시져를 트리거하는 역할 또는, 단순작업이 목적이라면 reader -> writer를 사용하는 청크지향처리 대신에 tasklet을 사용하는것이 좋습니다.