Spring batch를 사용하기위한 첫 단계
요청이 들어올때 마다 실시간으로 데이터를 처리 하는것이 아닌 일괄적으로 모아서 하는 작업을 배치 (Batch) 작업이라고 합니다. 이러한 특성때문에 배치작업은 일반적으로, ‘정해진 시간에 대량의 데이터를 일괄적으로 처리한다’는 특징을 갖습니다.
Spring에서는 Spring batch framework를 통해 배치작업을 위한 다양한 기능들을 간편하게 사용 할 수 있도록 제공 해 주고 있습니다.
그 중, Spring batch가 제공하는 가장 기본적인 기능으로 배치 작업 하는동안 사용되는 모든 메타정보들 (작업 시간, 파라미터, 정상수행 여부 …)을 기록하여 작업 중에 사용하거나 모니터링 용도로 사용 할 수 있게 해줍니다.
이러한 이유로 Spring batch를 사용하기 위한 ‘첫번째 단계’는 다름이 아닌 메타 데이터 스키마을 구성하는 것 입니다.

‘아무것도 모르는데 무슨테이블을 만들어야 하지…?’ 라고 생각하고 계신 분들도 할 수 있도록 친절한 Spring batch는, 서비스 시작시 자동으로 테이블을 구성 해 주기도 하고 문서를 통해 테이블 ERD와 DDL 스크립트를 함께 제공 해 주고 있습니다.
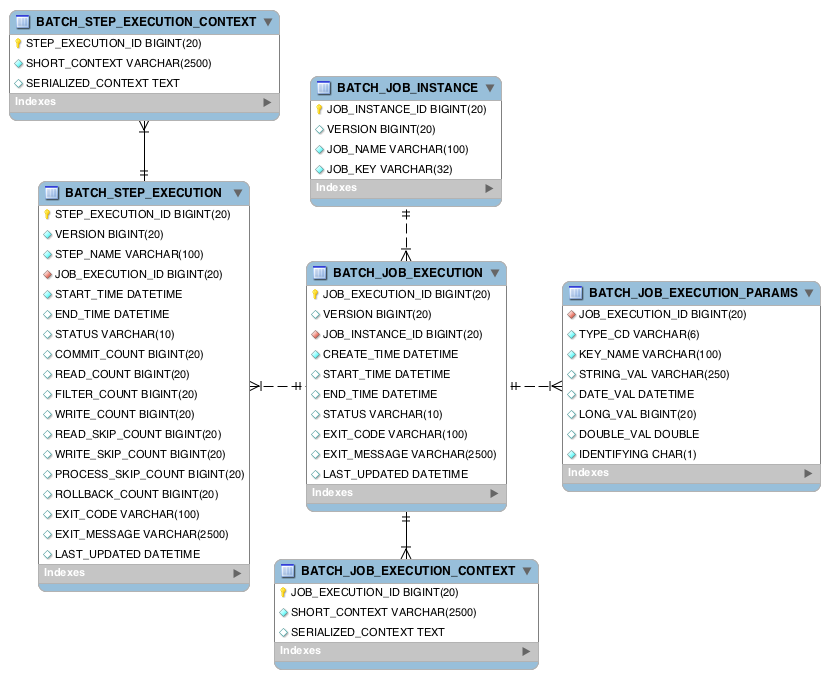
(https://docs.spring.io/spring-batch/docs/current/reference/html/schema-appendix.html)
Spring batch 메타테이블 정보
만약 위의 메타 데이터 스키마은 단순히 배치 작업의 결과를 기록하는 테이블이라고 생각하신다면 '배치작업에 굳이 이렇게까지 복잡한 테이블을 구성할 필요는 없는데...' 라고 생각하실 수도 있습니다.
하지만 이 테이블에 저장되는 데이터들은 단순히 모니터링 용도로만 사용되는 것이 아닌 실제 배치 작업을 하는동안 사용되는 데이터들이 저장되는 장소기때문에 각 테이블들에 어떤 데이터가 적재되는지 잘 알고 사용하시는 것이 좋습니다.
Spring batch에서 제공하는 메타 데이터 스키마은 총 6개의 테이블로 이루어져 있습니다. 이 테이블 구조만 파악해도 Spring batch에서 어떤 방식으로 Job을 처리하는지 어느정도는 파악 하실 수 있습니다.
데이터가 적재되는 순서는 위 ERD의 관계를 보시면 아시겠지만 아래와 같은 순서로 적재 될 것입니다.
- BATCH_JOB_INSTANCE
- BATCH_JOB_EXECUTION
- BATCH_JOB_EXECUTION_PARAM
- BATCH_JOB_EXECUTION_CONTEXT
- BATCH_STEP_EXECUTION
- BATCH_STEP_EXECUTIOIN_CONTEXT
각 테이블별로 어떤 데이터가 저장되는지 알아보겠습니다.
BATCH_JOB_INSTANCE
| 칼럼 | 설명 |
|---|---|
| JOB_INSTANCE_ID | Job 고유 ID |
| VERSION | 변경 버전정보 (update 될때마다 +1) |
| JOB_NAME | Job 빌드시 생성하는 이름 |
| JOB_KEY | Job 고유 키 (Job 중복 수행 체크를 위한 고유 키 로써, Job_name과 파라미터로 키값이 결정됨) |
배치 Job의 생성정보를 담는 테이블입니다.
BATCH_JOB_EXECUTION
| 칼럼 | 설명 |
|---|---|
| JOB_EXECUTION_ID | Job 실행 고유 ID |
| VERSION | 변경 버전정보 (update 될때마다 +1) |
| JOB_INSTANCE_ID | Job 고유 ID |
| CREATE_TIME | 생성 시간 |
| START_TIME | 시작 시간 |
| END_TIME | 종료 시간 |
| STATUS | 실행 상태 |
| EXIT_CODE | 종료 코드 |
| EXIT_MESSAGE | Job 수행 실패시 메세지 |
| LAST_UPDATED | 최종 업데이트 시간 |
| JOB_CONFIGURATION_LOCATION | Job config 설정 위치 |
배치 Job의 실행정보를 담는 테이블입니다.
Job의 전반적인 수행 여부 및 프로파일링을 할 수 있으며, 해당 테이블 구조를 통해 Job Instance 하나에 여러개의 Job Execution이 발생 할 수 있음을 짐작 하실수 있으실 겁니다.
BATCH_JOB_EXECUTION_PARAMS
| 칼럼 | 설명 |
|---|---|
| JOB_EXECUTION_ID | Job 실행 고유 ID |
| TYPE_CD | 저장된 값의 type (string, date, long, double) |
| KEY_NAME | 키 |
| STRING_VAL | string 값 |
| DATE_VAL | date 값 |
| LONG_VAL | long 값 |
| DOUBLE_VAL | double 값 |
| IDENTIFYING | Job Instance 생성시 관여 여부 플래그 |
빼치 Job에서 사용되는 파라미터값들을 담는 테이블입니다.
테이블에서 알 수 있다시피, String, Date, Long, Double 네가지 타입의 값만 사용이 가능하며, 해당 파라미터가 Job Instance 생성에 관여함을 확인 하실수 있습니다.
BATCH_JOB_EXECUTION_CONTEXT
| 칼럼 | 설명 |
|---|---|
| JOB_EXECUTION_ID | Job 실행 고유 ID |
| SHORT_CONTEXT | String 형태의 context |
| SERIALIZED_CONTEXT | serializied 된 전체 context |
작업중 사용되는 모든 정보가 기록되는 Context를 저장하기 위한 테이블입니다.
Job Execution 하나당 하나씩의 Job Execution Context를 갖게되며 해당 Context 정보를 통해 동일한 Job Scope내에서 데이터를 공유 할 수 있습니다.
BATCH_STEP_EXECUTION
| 칼럼 | 설명 |
|---|---|
| STEP_EXECUTION_ID | Step 실행 고유 ID |
| VERSION | 변경 버전정보 (update 될때마다 +1) |
| STEP_NAME | Step 이름 |
| JOB_EXECUTION_ID | Job 실행 고유 ID |
| START_TIME | 시작 시간 |
| END_TIME | 종료 시간 |
| STATUS | 실행 상태 |
| COMMIT_COUNT | 트랜잭션당 커밋수 |
| READ_COUNT | 조회한 item 수 |
| FILTER_COUNT | 필터링된 item 수 |
| WRITE_COUNT | 저장된 item 수 |
| READ_SKIP_COUNT | 조회 skip한 item 수 |
| WRITE_SKIP_COUNT | 저장 skip한 item 수 |
| PROCESS_SKIP_COUNT | skip된 item 수 |
| ROLLBACK_COUNT | 롤백 발생 횟수 |
| EXIT_CODE | 종료 코드 |
| EXIT_MESSAGE | Step 수행 실패시 메세지 |
| LAST_UPDATED | 최종 업데이트 시간 |
배치 Step의 실행정보를 담는 테이블입니다.
해당 테이블을 통해 Job Execution하위에 Step Execution이 만들어지고, 디테일한 배치 작업 정보들이 기록되는것을 확인 하실수 있습니다.
BATCH_STEP_EXECUTION_CONTEXT
| 칼럼 | 설명 |
|---|---|
| STEP_EXECUTION_ID | Step 실행 고유 ID |
| SHORT_CONTEXT | String 형태의 context |
| SERIALIZED_CONTEXT | serializied 된 전체 context |
Step에서 사용되는 모든 정보가 기록되는 Context를 저장하기 위한 테이블입니다.
BATCH_JOB_EXECUTION_CONTEXT테이블과 마찬가지로 Step Execution 하나당 하나씩의 Job Execution Context를 갖게되며 해당 Context 정보를 통해 동일한 Step Scope내에서 데이터를 공유 할 수 있습니다.
Spring batch 메타 데이터 스키마 안쓰는법
위에서 말씀드린 것 처럼 Spring batch를 사용하기 위해서는 위 메타테이블들을 구성하는것이 필수 입니다. 하지만 운영하고 계신 DB에 위 스키마들을 구성 하기 싫으시거나, 구성하지 못하시는분들도 분명 계실겁니다.
특히, 현재 Spring batch에서는 모든 DB에대해서 공식적으로 지원하지는 않기때문에 스키마를 쓰고싶어도 못쓰는 상황이 발생 할 수도 있습니다.
(공식적으로 지원 하는 DB는 아래와 같습니다.)
- DERBY ("Apache Derby")
- DB2 ("DB2")
- DB2VSE ("DB2VSE")
- DB2ZOS ("DB2ZOS")
- DB2AS400 ("DB2AS400")
- HSQL ("HSQL Database Engine")
- SQLSERVER ("Microsoft SQL Server")
- MYSQL ("MySQL")
- ORACLE ("Oracle")
- POSTGRES ("PostgreSQL")
- SYBASE ("Sybase")
- H2 ("H2")
- SQLITE ("SQLite")
이러한 경우에도 Spring batch를 사용 할 수 있는 2가지 방법이 있습니다.
바로, in-memory repository를 사용하거나 배치 전용으로 H2를 사용하는 방법입니다.
먼저, in-memory repository를 사용하는 방법은 아래와 같습니다.
@Configuration
@EnableBatchProcessing
public class BatchConfig extends DefaultBatchConfigurer
{
@Override
public void setDataSource(DataSource dataSource)
{
// 비어있는 메서드
// Spring batch 메타스키마가 in-memory repository를 사용합니다.
}
}
다음, H2를 사용하는 방법입니다.
@Configuration
@EnableBatchProcessing
public class BatchConfig extends DefaultBatchConfigurer
{
@Override
public void setDataSource(@Qualifier("h2Datasource") dataSource)
{
// H2 datasource를 batch 기본 datasource로 설정해줍니다.
super.setDataSource(dataSource);
}
}
다만, 위 두가지 방법을 사용하실 때 주의하셔야 할 점은 아시다시피 데이터가 메모리에 쌓이기때문에 데이터가 영속적이지 않다는 점이 있습니다. 만약 배치 스키마 데이터를 모니터링해야하는 요구사항이 있을경우에는 이 방법을 사용하시면 안됩니다.
또한, 데이터가 메모리에 쓰이기 때문에 배치 작업이 진행될 수록 메모리 공간을 점유하게 됩니다. memory overflow 이슈를 막기 위해서 주기적으로 데이터를 직접 제거해주는 작업 추가가 필요한 점을 주의하셔야 합니다.