java.nio는 java4 부터 java.io의 단점을 보완하기위해 추가된 패키지로 nio(new-io)라는 이름으로 등장 하였습니다.
(+ java7 부터 nio2를 통해 java.io와 java.nio가 추가 개선되었습니다.)
이번 포스팅에서는 File Read/Write 작업에 대해
java.io 를 사용 한 코드와 java.nio 를 사용한 코드를 직접 수행 하여 비교를 통해 성능 비교를 진행 해 보도록 하겠습니다.
java IO 수행 로직
성능 비교를 하기 전, 우선적으로 I/O를 할때 어떤 작업들이 수행되는지 row-level에서 알아보도록 하겠습니다.
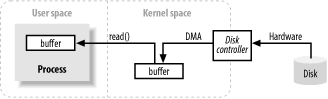 (출처 : https://howtodoinjava.com/java/io/how-java-io-works-internally/)
(출처 : https://howtodoinjava.com/java/io/how-java-io-works-internally/)
- Disk controller가 Disk 에서 데이터 read
- Disk controller가 커널 영역 메모리 버퍼에 데이터 write
- 커널은 사용자 영역 메모리 버퍼로 데이터를 copy
위의 로직에서 보시다시피 커널 메모리를 직접 접근하는 것이 아닌 JVM에 데이터를 copy하는 작업 로직이 포함되어 있기 때문에 비효율적이다는 의견이 있습니다.
일반적으로 DMA를 하게되면 CPU 자원사용 없이 직접적인 메모리 접근을 하기 때문에 CPU 오버헤드가 없으며 CPU 자원 점유가 없는 non-blocking 수행이 가능하다는 이점이 있습니다.
(https://en.wikipedia.org/wiki/Direct_memory_access)
java.nio 에서는 사용자 영역상에 Buffer를 만들어 사용하는것이 아닌 커널영역에 Buffer를 만들어 직접 DMA를 할 수 있도록 제공하고 있어 가능하다면 java.nio를 사용하는것이 java.io를 사용하는 것 보다 일반적으로 성능적으로 뛰어나다고 이야기되고 있는데요,
저 또한 I/O 성능이 중요한 프로젝트 작업중 팀 코드리뷰를 통해 의견을 받게되어 직접 테스트를 진행하게되었습니다.
Channel + Buffer
우선 java.nio에서 어떻게 DMA를 통한 File read를 할 수 있는지 코드로 알아보도록 하겠습니다.
public void readFile(Path filePath)
{
final int bufferSize = 1024*1024;
try (FileChannel channel = FileChannel.open(filePath, StandardOpenOption.READ))
{
ByteBuffer buffer = ByteBuffer.allocateDirect(bufferSize);
while ((channel.read(buffer)) >= 0) {
...
}
}
}
위와같이 ByteBuffer.allocateDirect()를 사용해 커널메모리영역에서 사용가능한 Buffer를 선언하여 간단하게 사용 할 수 있습니다.
다만 알아두셔야 할 점은 일반 buffer 보다 direct buffer를 선언할때 훨신 오랜 시간이 소요되기 때문에 선언한 buffer를 재사용 해야 하며
Channel은 Buffer 단위로만 데이터 통신이 일어나기 때문에 File read시 line 단위로 읽는 등의 작업을 할 때에는 Buffer 내에서 line 을 찾는등의 별도의 처리가 필요합니다.
성능테스트
우선 제가 진행하고 있는 프로젝트는 File의 line 단위로 처리되어야 해서 두가지 조건으로 테스트를 진행 해 볼 예정입니다.
- 첫번째 조건은, 조건없이 File을 read하여 새로운 File에 write
- 두번째 조건은, File을 read하여 line 단위로 새로운 file에 write
위 두가지 조건과 함께 io, nio 를 사용하면서 성능측정을 진행 해 보도록 하겠습니다.
즉, 얻고자하는 결과값을 표로 나타내보자면 아래와 같습니다.
| 바이트단위 (ms) | 라인단위 (ms) | |
|---|---|---|
| Read (io) & Write (io) | 테스트-1 | 테스트-3 |
| Read (nio) & Write (nio) | 테스트-2 | 테스트-4 |
대상 데이터 파일은 아래와 같습니다.
- test_ep_1.txt (약 280,000건 EP 상품 데이터, 200MB)
- test_ep_2.txt (약 20,000,000건 EP 상품 데이터, 12GB)
테스트-1 (단위 없음 / Read (io) & Write (io))
@Test
public void test_1()
{
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(SOURCE_FILE_PATH));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(RESULT_FILE_PATH, true));
)
{
int c;
while ((c = bis.read()) != -1)
{
bos.write(c);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
결과
- test_ep_1.txt → 7,034ms
- test_ep_2.txt → 198,509ms
테스트-2 (단위 없음 / Read (nio) & Write (nio))
@Test
public void test_2()
{
final int bufferMaxSize = 1024 * 1024;
Path sourceFilePath = Paths.get(SOURCE_FILE_PATH);
Path resultFilePath = Paths.get(RESULT_FILE_PATH);
try (FileChannel sourceChannel = FileChannel.open(sourceFilePath, StandardOpenOption.READ);
FileChannel resultChannel = FileChannel.open(resultFilePath, StandardOpenOption.WRITE, StandardOpenOption.CREATE, StandardOpenOption.APPEND);
)
{
ByteBuffer buffer = ByteBuffer.allocateDirect(bufferMaxSize);
while (sourceChannel.read(buffer) >= 0)
{
buffer.flip();
resultChannel.write(buffer);
buffer.clear();
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
결과
- test_ep_1.txt → 280ms
- test_ep_2.txt → 15,806ms
테스트-3 (Line 단위 처리 / Read (io) & Write (io))
@Test
public void test_3()
{
try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(SOURCE_FILE_PATH)));
BufferedWriter bw = new BufferedWriter(new FileWriter(RESULT_FILE_PATH, true));
)
{
String line;
while ((line = br.readLine()) != null)
{
bw.write(line);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
결과
- test_ep_1.txt → 1,602ms
- test_ep_2.txt → 79,968ms
테스트-4 (Line 단위 처리 / Read (nio) & Write (nio))
@Test
public void test_4()
{
final int bufferMaxSize = 1024 * 1024;
final byte lf = 0x0A;
Path sourceFilePath = Paths.get(SOURCE_FILE_PATH);
Path resultFilePath = Paths.get(RESULT_FILE_PATH);
try (FileChannel sourceChannel = FileChannel.open(sourceFilePath, StandardOpenOption.READ);
FileChannel resultChannel = FileChannel.open(resultFilePath, StandardOpenOption.WRITE, StandardOpenOption.CREATE, StandardOpenOption.APPEND);
)
{
long channelCursor = 0;
ByteBuffer buffer = ByteBuffer.allocateDirect(bufferMaxSize);
ByteBuffer writeBuffer = ByteBuffer.allocateDirect(bufferMaxSize);
int bufferReadSize;
while ((bufferReadSize = sourceChannel.read(buffer)) >= 0)
{
int bufferCursor = 0;
buffer.flip();
byte b;
try
{
while ((b = buffer.get()) != -1)
{
writeBuffer.put(b);
if (b == lf || (bufferReadSize < bufferMaxSize && buffer.position() + 1 == bufferReadSize))
{
writeBuffer.flip();
resultChannel.write(writeBuffer);
writeBuffer.clear();
bufferCursor = buffer.position();
}
}
}
catch (BufferUnderflowException e)
{
//skip
}
channelCursor += bufferCursor;
buffer.clear();
sourceChannel.position(channelCursor);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
결과
- test_ep_1.txt → 2,484ms
- test_ep_2.txt → 92,168ms
테스트-4_2 (Line 단위 처리 / Read (nio) & Write (io))
@Test
public void test_4_1()
{
Path sourceFilePath = Paths.get(SOURCE_FILE_PATH);
try (BufferedReader br = Files.newBufferedReader(sourceFilePath);
BufferedWriter bw = new BufferedWriter(new FileWriter(RESULT_FILE_PATH, true));
)
{
String line;
while ((line = br.readLine()) != null)
{
bw.write(line);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
결과
- test_ep_1.txt → 1,975ms
- test_ep_2.txt → 143,093ms
테스트-4_2 (Line 단위 처리 / Read (nio) & Write (io))
@Test
public void test_4_1()
{
final int bufferMaxSize = 1024 * 1024;
final byte lf = 0x0A;
Path filePath = Paths.get(SOURCE_FILE_PATH);
try (FileChannel channel = FileChannel.open(filePath, StandardOpenOption.READ);
BufferedWriter bw = new BufferedWriter(new FileWriter(RESULT_FILE_PATH, true));
)
{
int channelCursor = 0;
ByteBuffer buffer = ByteBuffer.allocateDirect(bufferMaxSize);
while (channel.read(buffer) >= 0)
{
int bufferReadSize = buffer.position();
int bufferPosition = bufferReadSize;
buffer.flip();
while (bufferPosition > 0)
{
if (buffer.get(bufferPosition - 1) == lf)
{
break;
}
else
{
bufferPosition--;
}
}
buffer.limit(bufferPosition);
channelCursor += bufferPosition;
String lines = StandardCharsets.UTF_8.decode(buffer).toString();
String[] lineList = lines.split("\\n");
for (String line : lineList)
{
bw.write(line);
}
buffer.clear();
channel.position(channelCursor);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
결과
- test_ep_1.txt → 1,975ms
- test_ep_2.txt → 89,769ms
테스트 결과
테스트 내용을 정리해보면 아래 표와 같습니다.
test_ep_1.txt (약 280,000건 EP 상품 데이터, 200MB)
| 바이트단위 (ms) | 라인단위 (ms) | |
|---|---|---|
| Read (io) & Write (io) | 7,034 | 1,602 |
| Read (nio) & Write (nio) | 280 | 3,358 |
| Read (nio) & Write (io) | 2,484 (newBufferedReader) |
|
| Read (nio) & Write (io) | 1,975 |
test_ep_2.txt (약 20,000,000건 EP 상품 데이터, 12GB)
| 바이트단위 (ms) | 라인단위 (ms) | |
|---|---|---|
| Read (io) & Write (io) | 198,509 | 79,968 |
| Read (nio) & Write (nio) | 15,806 | 143,093 |
| Read (nio) & Write (io) | 92,168 (newBufferedReader) |
|
| Read (nio) & Write (io) | 89,769 |
위 결과로 보면 Byte 단위 read/write 수행시에는 처음에 예상 했던 것 처럼 java.nio DMA 를 활용하는것이 월등한 성능(5~25배)을 보이는것이 확인 되었습니다.
하지만 Byte 단위가 아닌 Line 단위로 데이터를 처리해야 할 때는, Byte에서 Line 찾아야하는 로직이 추가로 들어가면서 오히려 bufferedReader를 사용한 java.io 보다 성능이 떨어지는 현상이 확인되었습니다.
만약 수행로직이 1,000,000 line씩 한번에 Write 하는 등 사이즈를 크게잡아 수행한다면 nio 처리 성능이 더 빠르게 나올 것으로 기대가 되지만 제가 작업중인 프로젝트에서 필요한 로직으로는 File 에서 line by line으로 처리해야되는 로직이 포함되어 있어 위와 같은 테스트 결과를 도출해 내었습니다.
결론
- Byte 단위 File 처리 → java.nio (DMA buffer)
- Line 단위 File 처리 → java.io (BufferedReader)
해당 내용과 관련해서 비슷한 테스트를 진행한 블로그 내용을 발견하여 함께 첨부합니다. (https://funnelgarden.com/java_read_file/)