reactive vs imperative
저를 포함한 대부분의 독자분들 께서는 reactive라 하면 늘 찬양하는 글과 발표주제들을 보셨을 겁니다. 소개 내용을 보면 효율적이고 멋진 프로그래밍을 할 수 있어보이지만 실제로 실무환경에서 reactive를 적용시켜보기에는 어려운점이 많으셨을거라 생각합니다.
이번 포스팅에서는 reactive의 정확한 의미와 사용범, 그리고 어떤 상황에서 reactive를 효율적으로 사용 할 수 있을지에 대해서 알아보도록 하겠습니다.
reactive와 대조되는 개념은 전통적인 프로그래밍 방식인 절차적 (imperative) 방식 입니다. 용어만으로는 이해하기 어려울것같아 한가지 비유를 해보도록 하겠습니다.
‘물을 전달한다’ 라는 같은 목적을 가지고 두가지 방법의 처리 방법을 정리해보면 다음과 같습니다.
1. 물풍선
물을 틀어 풍선에 채운다 -> 풍선을 던진다.2. 호스
물을 틀면서 물을 뿌린다.
물을 풍선에 다 채워야만 물을 전달 할 수 있는 물풍선 (imperative)와는 다르게, 물이 나오는대로 전달 할 수 있는 호스 (reactive)의 차이를 생각해보시면 조금더 이해가 쉬우실거라 생각합니다.
이제 reactive가 개발적으로 갖는 의미를 정의해보기위해 먼저 reactive가 탄생하게된 배경부터 알아보도록하겠습니다.
사실 reactive라 하면 일반적으로 reactive programming의 개념으로써, 단순히 프로그래밍의 방법중의 하나로 인식 할 수도 있지만 전체적인 시스템적인 관점에서 reactive를 함께 이해하는것이 좋습니다.
다음은 reactive 선언서의 일부를 발췌한 내용입니다. (원문 : https://www.reactivemanifesto.org/)
Today applications are deployed on everything from mobile devices to cloud-based clusters running thousands of multi-core processors. Users expect millisecond response times and 100% uptime. Data is measured in Petabytes. Today’s demands are simply not met by yesterday’s software architectures.
…
we want systems that are Responsive, Resilient, Elastic and Message Driven. We call these Reactive Systems.
결국, 리액티브는 수많은 사용자에게 빠르고 높은 응답률을 일관되게 보장해주기 위해 고안된 아키텍쳐로써
- 일관적인
응답성(responsive) - 장애에 빠르게 대응 할 수있는
복원성(resilient) - 리소스를 변경해 부하를 탄력적으로 조절 할 수있는
탄력성(Elastic) - 탄력적인 리소스 전달을 위한
메세지 기반(message driven)
위 의 특징을 가진 시스템 이라 할 수 있겠습니다.
그렇다면 reactive를 통해 imperative와 비교하여 실제적으로 어떤 장점을 얻을수 있을까요?
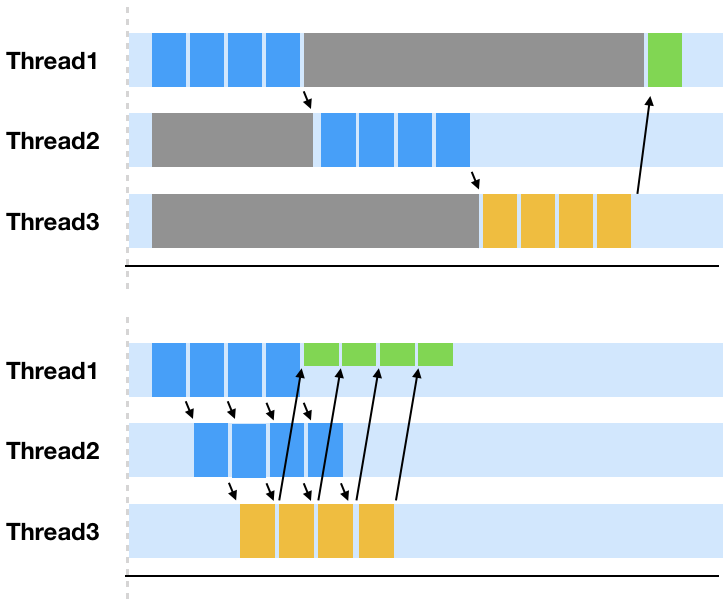
설명을 위한 위 예제 상황의 그림이 조금은 억지(?)스러운 상황이라 보실수도 있겠지만 위에서 언급한 reactive의 일관적인 응답성에 대해 너무나 명확히도 보여주는 다이어그램 입니다.
또, 다이어그램을 보시면서 느끼셨겠지만 여기서 주목해야 할 점은 Thread1 -> Thread2 -> Thread3로 이어지는 하나의 흐름을 만들어 자원을 빈틈없이 효율적으로 이용할 수 있다는 점입니다.
위와같이 blocking으로 인해 유휴자원이 많이 발생하는 서비스의 경우 reactive programming을 적용한다면 큰이점을 얻을 수 있으실거라 생각됩니다.
reactive programming
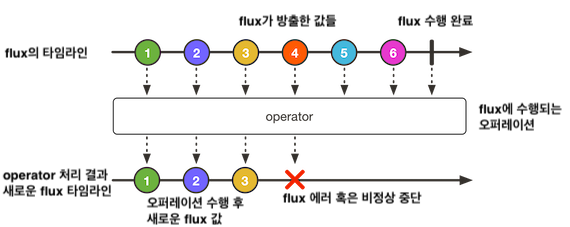
위 다이어그램은 리액티브 플로우를 나타내주는 마블 다이어그램 입니다. reactive programming에서 사용되는 단위인 Flux와 Mono의 처리 흐름을 보여주는 다이어그램으로, 사실 익숙하지 않으시다면 단번에 이해하시기는 어려우실거라 생각됩니다.
먼저 위 다이어그램을 통해 reactive programming flow에 대해서 알아보도록 하겠습니다.
리액티브 플로우는 다음 3개의 작업을 통해 수행된다고 볼 수 있습니다.
-
발행 (publish)
reactive flow에서 사용할 소스를 만들어 냅니다. -
작업 (operate)
reactive flow에서 처리할 작업을 정의합니다. -
구독 (subscribe)
reactive flow에서 처리된 결과를 정의합니다.
위의 flow를 개발상에서 구현을 위해 구체화 시킨 것이 netflix, lightbend, pivotal 엔지니어들이 만든 reactive stream 입니다.
reactive stream은 다음과같은 4개의 인터페이스로 구성됩니다.
- Publisher (발행자)
public interface Publisher<T> { void subscribe(Subscriber<? super T? subscriber>); } - Subscriber (구독자)
public interface Subscriber<T>
{
void onSubscribe(Subscription sub);
void onNext(T item);
void onError(Throwable ex);
void onComplete();
}
- Subscription (구독)
public interface Subscription
{
void request(long n);
void cancel();
}
- Processor (프로세서)
public interface Processor<T,R> extends Subscriber<T>, Publisher<R>
{
}

Subscriber는Publisher에게 구독신청(subscirbe) 한다.Publisher는Subscriber에게Subscribtion의 전달과 함께 구독 발행((onSubscribe) 을 알린다Subscriber는 데이터를 요청(Subscribtion.request)하거나 취소(Subscribtion.cancel) 한다.Publisher는Subscriber에게 다음 데이터를 전달 (onNext) 한다.Subscriber는 전달받은 데이터를 처리후 다음 데이터를 요청(request)하거나, 에러가 났음(onError)을 알린다.Publisher는Subscriber에게 발행이 끝남(onComplete)을 알린다.
reactive stream을 사용한 실제 에제 확인하기 전에 먼저, Flux와 Mono에 대해 알아보겠습니다.
Flux와 Mono는 위의 reactive stream의 4개의 interface중 Publisher의 구현체입니다.
package reactor.core.publisher;
public abstract class Flux<T> implements Publisher<T> {
...
}
public abstract class Mono<T> implements Publisher<T> {
...
}
Flux와 Mono는 reactive stream에서 데이터를 발행하는 pulisher의 역할을 하며, 발행하는 데이터 갯수에서 차이를 갖습니다.
Flux의 경우 0-N개 즉, 여러개의 데이터를 발행하고자 할때 사용되며, Mono는 0-1개 즉, 단일의 데이터를 발행하고자 할때 사용되는 publisher입니다.
아래 간단한 예제를 통해 좀더 자세히 알아보도록 하겠습니다.
@Test
void fluxExample1()
{
List<String> names = new ArrayList<>();
names.add("andrew");
names.add("banana");
names.add("chicago");
names.add("daniel");
names.add("e-bay");
names.add("facebook");
names.add("google");
names.add("home");
names.add("iphone");
names.add("juran");
names.add("kakao");
Flux.just(names.toArray(new String[0])).log()
.map(name -> name.toUpperCase())
.subscribeOn()
.subscribe(
new Subscriber<String>()
{
private Subscription subscription;
long maxCount = Long.MAX_VALUE;
@Override
public void onSubscribe(Subscription subscription)
{
System.out.println("Regist subscription");
this.subscription = subscription;
this.subscription.request(maxCount);
}
@Override
public void onNext(String o)
{
idx++;
System.out.println("UPPER-" + o);
}
@Override
public void onError(Throwable t)
{
}
@Override
public void onComplete()
{
System.out.println("Complete");
}
}
);
}
위 코드는 다음과 같이도 표현 할 수 있습니다.
Flux.just(names.toArray(new String[0])).log()
.map(name -> name.toUpperCase())
.subscribe(
name -> System.out.println("UPPER-" + name)
, null
, () -> System.out.println("Complete")
);

로그 결과를 보면 정의한대로 reactive 하게 동작하지만, 위 다이어그램과는 다르게 request에 unbounded 값이 들어가 onSubscribe()를 할 때 publisher로 부터 무한대의 구독 아이템을 받아서 처리하게 됩니다.
여기서 request의 역할은 publisher의 발행 아이템 갯수를 조절해 subscriber에게 과부하가 일어나지 않게 조절 해 주는 역할을 해줍니다. 이것이 reactive stream의 주요 기능 중 하나인 backpressure(역압)이라고 합니다.
backpressure를 적용한 코드는 다음과 같습니다.
@Test
void fluxExample1()
{
// given
List<String> names = new ArrayList<>();
names.add("andrew");
names.add("banana");
names.add("chicago");
names.add("daniel");
names.add("e-bay");
names.add("facebook");
names.add("google");
names.add("home");
names.add("iphone");
names.add("juran");
names.add("kakao");
//when
Flux.just(names.toArray(new String[0])).log()
.map(name -> name.toUpperCase())
.subscribe(
new Subscriber<String>()
{
private Subscription subscription;
int idx = 0;
@Override
public void onSubscribe(Subscription subscription)
{
System.out.println("Regist subscription");
this.subscription = subscription;
this.subscription.request(3);
}
@Override
public void onNext(String o)
{
idx++;
System.out.println("UPPER-" + o);
if (idx % 3 == 0)
{
subscription.request(3);
}
}
@Override
public void onError(Throwable t)
{
}
@Override
public void onComplete()
{
System.out.println("Complete");
}
}
);
}

backpressure를 적용하고나니 이제 위 다이어그램의 로직과 정확히 똑같은 실행 결과를 확인 하실 수 있습니다.
위에서는 매우 간단한 예제를 보여드려서 ‘이걸 실무에서 어떻게 쓰지?’라고 생각하실 수 있을것 같아 실무에서 사용 한 예제 하나를 보여드리겠습니다.
public void deleteRedisSetKey()
{
String key = "setKey";
reactiveCommands.smembers(key)
.subscribeOn(Schedulers.elastic())
.subscribe(
value -> reactiveCommands.del(value)
, null
, () -> reactiveCommands.del(key)
);
}
저희팀에서는 Redis를 다음과 같은 구조로 사용하고 있습니다.
| key | value |
|---|---|
| A | set {a,b} |
| a | 100 |
| b | 200 |
| B | set {c,d} |
| c | 300 |
| d | 400 |
위와 같은 상황에서 key A를 삭제할때, set 자료구조에 저장되어있는 실제 키 값들을 함께 삭제해주어야 하는데, 이때 set의 전체 value들을 가져오는 smembers 명령을 통해 reactive 하게 데이터를 가져와 각각의 key들을 del 명령을 통해 삭제해주고, 해당 명령이 모두 완료 된 후에 del명령을 통해 set key를 삭제해주는 작업을 진행 해 줄 수 있습니다.
etc) java stream vs reactive stream
사실 java stream과 reactive stream은 형태도 , 다수의 공유되는 operation(map, flatmap…), 사용법등 많은 유사성을 가지고 있습니다.
차이점이라고 하면, java stream의 경우 ‘한정된 데이터’ stream으로 만들어 작업을 수행한다는 점에 있습니다. reactive stream은 제한 없는 데이터 셋 (무제한 데이터)의 비동기 처리를 지원 하는점에서 가장 큰 차이점을 가지고 있다고 보시면 될 것 같습니다.
reactive의 성능
'그렇다면 과연 reactive를 사용하면 실제로 성능이 빠른가?'
위에 대한 질문에 답하기위해 테스트를 진행해 보았습니다.
csv file을 일반 imperative, reactive 두가지 방식으로 읽어 처리하는 코드를 구현해 보았습니다.
long start;
long finish;
long finishFirst;
long firstFinishProcess;
long finishProcess;
@BeforeEach
void before() {
start = System.currentTimeMillis();
}
@AfterEach
void after() {
finish = System.currentTimeMillis();
finishProcess = finish - start;
firstFinishProcess = finishFirst - start;
System.out.println("start : " + start);
System.out.println("finishFirst : " + finishFirst);
System.out.println("firstFinishProcess : " + firstFinishProcess);
System.out.println("finish : " + finish);
System.out.println("finishProcess : " + finishProcess);
}
@Test
void blockReadTest() throws IOException {
List<String> list = new ArrayList<>();
try (BufferedReader br = Files.newBufferedReader(Paths.get("src/test/resources/csvFile.txt"))) {
String s = null;
while ((s = br.readLine()) != null) {
list.add(s);
}
}
list.stream()
.forEach(line ->
{
if (finishFirst == 0) finishFirst = System.currentTimeMillis();
String[] tokens = line.split(",");
// do something
}
);
}
@Test
void reactiveReadTest() throws IOException {
// resource
BufferedReader br = Files.newBufferedReader(Paths.get("src/test/resources/csvFile.txt"));
Flux<String> flux = Flux.create((FluxSink<String> sink) -> {
try {
String s = null;
while ((s = br.readLine()) != null) {
sink.next(s);
}
sink.complete();
} catch (IOException e) {
sink.error(e);
}
});
flux.subscribe(line -> {
if (finishFirst == 0) finishFirst = System.currentTimeMillis();
String[] tokens = line.split(",");
// do something
}
, null
, ()-> {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
);
}
blockReadTest 결과
csv 50,000 건

csv 100,000 건

reactiveReadTest 결과
csv 50,000 건

csv 100,000 건

정확한 비교가 가능할만한 좋은 코드는 아니지만, 위 프로파일링 결과를 확인해보면 성능차이를 확인 할 수 있습니다. 특히나, 중요하게 보셔야 할 것은, reactive에서는 처리 건 수가 변동되어도 첫번째 응답에 대한 시간이 거의 변동이 없었다는 것 입니다.
이것은 처음에도 말씀드렸던 reactive의 일관된 응답성을 확인 할 수 있는 내용입니다.
이뿐만 아니라, 로컬 환경에서 직접 검증을 해드리기는 어렵지만, 데이터를 한번에 모아서 처리하지 않기때문에 memory, cpu 자원 역시 효율적으로 사용 될 수 있다는 점 도 유추 하실 수 있으실것 같습니다.
그렇다면 여기서 리액티브코드가 다음과 같이 변경되면 어떤 결과가 나올까요?
List<String> list = new ArrayList<>();
try (BufferedReader br = Files.newBufferedReader(Paths.get("src/test/resources/csvFile.txt"))) {
String s = null;
while ((s = br.readLine()) != null) {
list.add(s);
}
}
Flux.just(list.toArray(new String[0]))
.subscribe(line -> {
if (finishFirst == 0) finishFirst = System.currentTimeMillis();
String[] tokens = line.split(",");
// do something
}
, null
, null
);
COUNT = 100_000

reactive stream 구성중 하나의 blocking 구간이 생긴것인데, 사실상 blocking 한구간 때문에 정상적인 sream이 구성되지 않아 오히려 그냥 수행한 것 보다 더 좋지 않은 결과가 나온 것을 확인 하실 수 있습니다.
reactive 도입을 고려하실때, ‘전 구간이 reactive하게 동작 할 수 있는가?’를 반드시 고려해 주셔야 할 사항입니다.