Redis 메모리 에러
저희팀에서는 상품 판별을 위해 DB 앞단에 Redis를 두고 상품정보를 persistant 하게 관리하고 있습니다. 그렇게 상품건수가 2억 5천만건을 넘어가던 어느날 Reedis에서 다음과 같은 에러가 발생하면서 정상적인 데이터 처리에 실패 했습니다.
MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error.
위 에러의 원인은, redis는 persistant를 유지하기 위해 주기적으로 bgsave를 통한 rdb를 저장하게되는데, 이 과정에서 메모리가 부족하여 발생하는 현상입니다.
위 에러를 구글링 해 보면 많은 답변으로써 'stop-writes-on-bgsave-error no 옵션을 통해 rdb 를 종료..' 와 같은 해결방법을 제시하지만, 해당 방법은 redis를 persistant 하게 사용하지 않고 단순한 캐시용도로만 사용할때만 적용 가능한 옵션입니다.
따라서 이 문제를 해결하기위해서는 결국 메모리 여유 공간을 늘려는 수 밖에 없습니다.
가장 간단하게 인스턴스 스케일업을 하는 방법이 있겠지만, 이미 꽤나 고사양의 인스턴스를 사용하고 있기때문에 메모리용량을 늘리기 보다는 데이터 타입을 변경하여 메모리를 좀 더 효율적으로 사용해 보는 쪽으로 시도해보았습니다.
이번 포스팅에서는 Redis 데이터 자료구조 변경을 통해 메모리 사용 효율을 개선시킨 사례를 공유드리고자 합니다.
레디스 Key overhead
위에서 자료구조의 변경을 통해 메모리를 절약 할 수 있다고 생각했던것은, Redis가 데이터를 저장할때 Key값에 대해서 Overehead가 발생하기 때문에, 레디스 상에서 관리되는 Key의 갯수를 줄일수 있다면 메모리를 절약 할 수 있을것으로 판단했기 때문입니다.
레디스 버전별로 계산되는 메모리 사용량은 조금씩 차이가 있지만, 데이터가 차지하는 Type별 Memory 사용량은 다음과 같습니다.
String Type
- (
Key Overhead: 50 Byte) + key size + (String Overhead: xx Byte) + value size
List Type
- (
Key Overhead: 50 Byte) + key size + (List Overhead: xx Byte) + value size
Set Type
- (
Key Overhead: 50 Byte) + key size + (Set Overhead: xx Byte) + value size
Hash Type
- (
Key Overhead: 50 Byte) + key size + field size + (Hash Overhead: xx Byte) + value size
위와같이 자료구조별로 저장 데이터 메모리 사용량이 계산되는 방식은 다릅니다만 공통적으로 꽤나 큰 Key Overhead를 가지고 있기때문에 Key자체가 많아질수록 오버헤드로 인해 메모리의 저장 용량은 커지게 될 수 밖에 없는 구조일것입니다.
(Redis 버전별로 Overhead의 차이가 있어 수치 값을 정확하게 표현하지는 않았습니다)
따라서 기존에 2억여개의 String Type data를 다른 자료구조로 변경하게된다면 하나의 key로 여러개의 value를 관리 할 수 있기 때문에 분명히 메모리 사용량을 줄일수 있을것입니다.
이 개선 프로젝트에서는 상품의 모든 key별로 매칭되는 value들을 유지 할 수있고, 값 조회에 유리한 Hash 자료구조로 마이그레이션을 하려고 합니다.
레디스 memory 사용량 테스트
자료구조별 메모리 사용량을 직접 테스트 해 보기 위해 환경을 구축하고 메모리 사용량을 측정해보도록 하겠습니다.
(테스트에는 현재기준 최신버전의 Redis:6.0.5 를 사용 합니다.)
String Type Memory usage
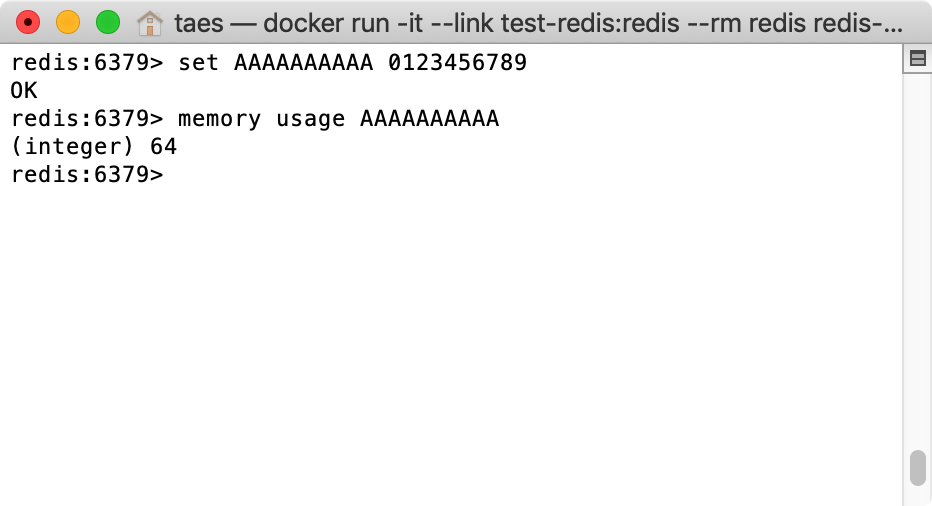
- Key : AAAAAAAAAA
- Value : 0123456789
- Memory Usage : 64
Hash Type Memory usage
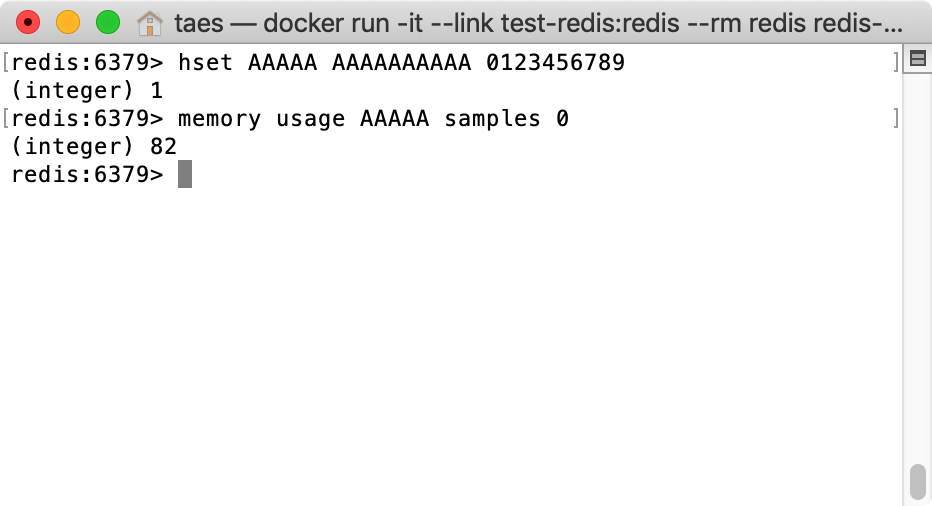
- Key : AAAAA
- Field : AAAAAAAAAA
- Value : 0123456789
- Memory Usage : 82
여기서 AAAAA Key에 데이터가 하나 더 추가된다면 메모리 사용량은 어떻게될까요?
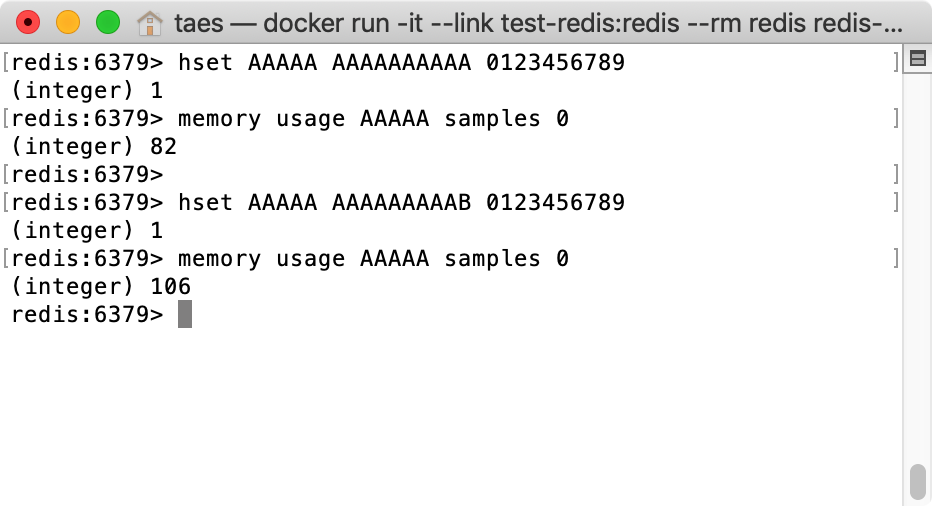
- Key : AAAAA
- Field : AAAAAAAAAA, AAAAAAAAAB
- Value : 0123456789, 0123456789
- Memory Usage : 106
데이터 하나만을 비교했을때는 Hash type이 메모리 사용량이 많았지만, 두개 이상부터는 하나의 key로 여러개의 value를 저장 할 수 있는 hash의 메모리 사용량이 현저하게 줄어들것을 예측 할 수 있습니다. (저장 데이터에 따라 임계갯수는 달라질수 있습니다)
String type 2개 를 저장했을때와 비교한다면 벌써부터 Hash를 사용했을때 메모리사용량이 줄어든것을 확인하실수 있으실것 같습니다.
- String type 2 data : 128
- Hash Type 2 data(1 key) : 106
데이터가 쌓이는 구조를 검증하기위해 위에서 데이터 단건의 메모리 사용량을 테스트 해보았는데, 이번에는 대량의 데이터로 테스트를 해보도록 하겠습니다.
테스트 데이터는 다음과 같습니다.
| Key | Value |
|---|---|
| 000000 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| 000001 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| … | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| 999999 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
위와같은 100만개의 String type 데이터를 아래의 Hash type으로 변경할때 메모리 사용량을 비교해보도록 하겠습니다.
| Key | Field | Value |
|---|---|---|
| 000 | 000000 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| 000 | 000001 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| 000 | … | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| 001 | 001000 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| … | … | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| 999 | 999999 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
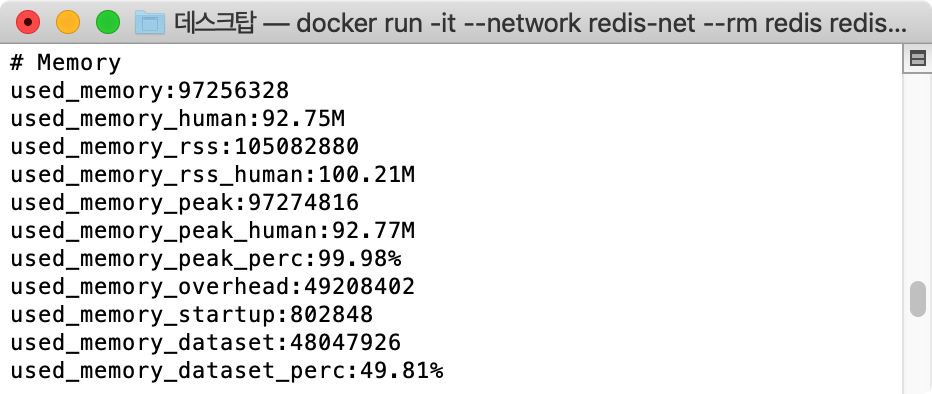
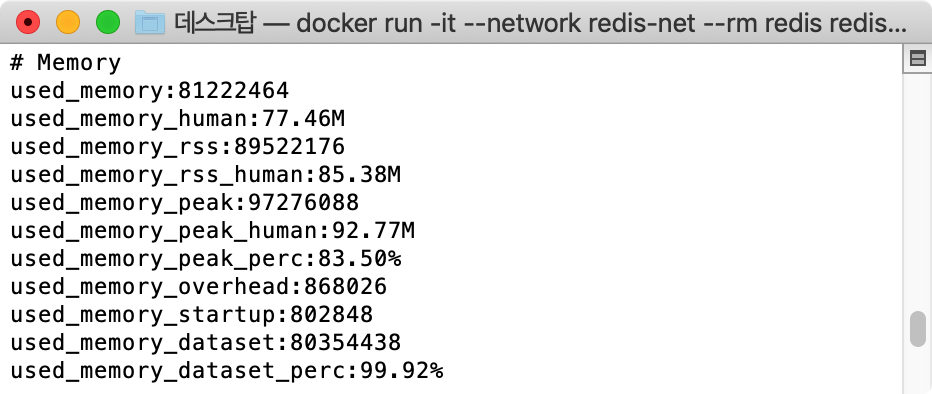
- String Type Memory Usage : 92.75M
- Hash Type Memory Usage : 77.46M
자료구조를 변경 한 것으로 약 15%의 메모리가 절약된것을 확인 할 수 있습니다. 테스트 케이스에서는 100만건을 대상으로 하여 그다지 큰 변화가 없어보이지만, 데이터수가 많아 질 수록 더 큰 효과를 확인 하실 수 있을겁니다.
실 서버 적용 결과
실 서버에서 사용되고 있는 데이터는 위 테스트 예제로 사용했던 데이터와 비슷한 형식으로 구성되어있습니다.
다만 Hash key를 구성할때 기존 key의 앞 5자로 생성하여 최대 16^5 = 1,048,576 개 (Hex)의 키 가 생성 될 것 입니다.
특히나 여기서 주의해야 할 점은 해시 구성시 설정된 필드 갯수 (hash-max-ziplist-entries 512)가 넘어가게되면 zip 자료구조에서 hashtable로 변경되기 때문에 키당 필드가 max-entry값을 넘지 않도록 해야 합니다.
(키값이 잘 분포되어있다는 가정하에, 2억 / 16^5 = 약 200개)
As-is의 Memory 사용량은 다음과 같습니다.
- shard1 : 40G
- shard2 : 50G
- shard3 : 38G
To-be의 Memory 사용량은 다음과 같습니다.
- shard1 : 31G
- shard2 : 36G
- shard3 : 25G
Redis 총 메모리 사용량의 변화는 128G -> 92G 로써, 약 30%의 메모리가 절약 되었습니다.
사실 실제 서비스에서는 Redis에 상품키 2억여건 이외에도 다른 데이터들이 많이 저장되어 있어 자료구조 변경으로 절약된 메모리 사용량을 정확히 을 계산 할 수는 없었습니다만 자료구조의 변경으로 메모리 사용량이 줄어든것을 확인 할 수 있었습니다.
후기
사실 메모리 개선작업을 진행하면서 가장 어려웠던것은, 기존 서비스에는 영향이 없도록 하면서 마이그레이션을 진행하는 작업이었습니다만 다행히도 한번에 성공하여 롤백시키는 불상사는 일어나지 않았습니다.
똑같은 데이터라도, 저장하는 자료구조에 따라서 메모리 사용량이 크게 좌우 될 수 있음을 인지하시고 혹시나 Redis를 통해 대용량 데이터를 관리 하실 예정이라면, 미리 메모리 사용량 까지 잘 고려하셔서 설계하시면 좋을것 같습니다.