InnoDB Lock
MySql InnoDB 엔진의 경우 다양한 Lock을 이용하여 ACID(원자성, 일관성, 고립성, 지속성) 및 동시성을 보장합니다.
Lock을 쿼리마다 사용자가 명시적으로 걸어 줄 수도 있지만, 일반적으로 Transaction isolation level에 따라 Lock을 걸어주게 되는데,
level에 따른 lock을 거는 상황들과 특히나 일반적이지 않은 상황에서 lock을 걸어 deadlock 까지 유발 할 수 있는 특수한 상황들을 알알아보도록 하겠습니다.
(해당 포스팅은 Mysql 5.7버전을 기준으로 합니다.)
Shared Lock & Exclusive Lock
innoDB storage engine은 기본적으로 Row-level lock을 사용합니다.
lock을 걸때는 query의 목적에 따라서 두가지 Type의 Lock을 사용하게 되는데 Read에 대한 Shared Lock (이하 S-lock)과 Write에 대한 Exclusive Lock 이하 X-lock입니다.
위와같이 Lock Type을 나누어 사용하는 이유는 Read끼리는 경쟁에서 자유로울수 있지만, Write에 대한 경쟁은 제한 시켜주기 위함입니다.
간단하게 lock type에 따른 경쟁 여부 관계를 테이블로 나타내면 다음과 같습니다.
| S-Lock | X-Lock | |
|---|---|---|
| S-Lock | X | O |
| X-Lock | O | O |
Locks
innoDB는 Row-lock을 기반으로 Lock을 걸게됩니다.
Lock에 대해서 다양한 해석이 있어 정확한 내용을 전달드리기 위해 MySQL공식 문서에서 설명하고 있는 내용으로 바탕으로 정리해보겠습니다.
Lock을 설명하기 위해 다음과 같은 예시 테이블과 데이터가 있다고 가정해보겠습니다.
Table Name : a_table
pk id name number age tel 10 taes 김태성 1 21 010-0000-0000 11 taesk 김태성 2 29 010-0000-0000 13 luke 루크 1 21 010-1111-0000 14 lukek 김루크 1 29 010-1111-0000 20 tester 테스터 1 33 010-0000-0000
- pk_idx(pk)
- id_unq_idx(id)
- name_number_unq_idx(name,no)
- name_age_idx(name,age)
1. Record Lock
A record lock is a lock on an index record.
개별 인덱스 레코드에 S-Lock 혹은 X-Lock을 설정하는 것입니다.
테이블에 인덱스가 생성되어 있지 않더라도 테이블 생성시에 함께 생성되는 default Clustered Index의 레코드에 Lock을 걸어, 항상 인덱스 레코드에 Lock을 설정합니다.
SELECT * FROM a_table WHERE pk=10 LOCK IN SHARE MODE
## -> pk=10 하나의 레코드에 S-Lock이 걸림
UPDATE a_table SET name='김수정' WHERE id='taes'
## -> id='taes' 하나의 레코드에 X-Lock이 걸림
2. Gap Lock
A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record
…
Gap locks in InnoDB are “purely inhibitive”, which means that their only purpose is to prevent other transactions from inserting to the gap.
레코드에 lock을 거는것이 아닌, 레코드간의 gap에 대해 Lock을 거는것으로 레코드간의 gap 에 새로운 Insert가 되는 현상을 방지하는 lock 입니다. 이와 더불어, 위 원문에서도 말하고있다시피 최초 레코드의 이전, 마지막 레코드의 이후의 gap 에도 lock을 설정합니다.
SELECT * FROM a_table WHERE pk BETWEEN 10 AND 15 FOR UPDATE;
## 위 쿼리로 다음과같은 gap 들에 X-Lock이 설정됩니다.
## - pk < 10 (최초레코드 이전의 gap)
## - 10 < pk < 11
## - 11 < pk < 13
## - 13 < pk < 14
## - 14 < pk < 20 (마지막레코드 이후의 gap)
다음과같은 상황에서는 Gap lock은 설정되지 않습니다.
Gap locking is not needed for statements that lock rows using a unique index to search for a unique row. (This does not include the case that the search condition includes only some columns of a multiple-column unique index; in that case, gap locking does occur.)
생각해보면 어쩌면 당연하겠지만, Unqiue 인덱스의 unique 한 row를 찾을때는 gap lock이 설정되지 않습니다.
SELECT * FROM a_table WHERE id='taes' FOR UPDATE;
## -> gap lock 설정되지 않음
SELECT * FROM a_table WHERE name='김태성' FOR UPDATE;
## -> name_number_unq_idx 에서 gap lock 설정 될 수 있음
3. Next-key Lock
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
Next-key Lock은 위에서 알아본 record lock과 gap lock을 함께 사용하는 lock 입니다.
SELECT * FROM a_table WHERE pk BETWEEN 10 AND 15 FOR UPDATE;
## 위 쿼리로 다음과같은 gap 들에 X-Lock이 설정됩니다.
## - pk = 10, 11, 13, 14, 20 [record x-lock]
## - pk < 10 (최초레코드 이전 gap) [gap x-lock]
## - 10 < pk < 11 [gap x-lock]
## - 11 < pk < 13 [gap x-lock]
## - 13 < pk < 14 [gap x-lock]
## - 14 < pk < 20 (마지막레코드 이후 gap) [gap x-lock]
By default, InnoDB operates in REPEATABLE READ transaction isolation level. In this case, InnoDB uses next-key locks for searches and index scans, which prevents phantom rows (see Section 14.7.4, “Phantom Rows”).
InnoDB의 default isolation level인 REPEATABLE READ에서는 phatom read를 막기위해 탐색시 next-key lock을 사용합니다.
원문 : https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-next-key-locks
Isolation level에 따른 Lock
InnoDB에서는 여러 트랜잭션이 경쟁시에 데이터의 일관성 유지 및 동시성 성능 유지를 위해 Lock을 사용하게 되는데, lock을 거는 조건들을 다르게 설정함으로써 4가지의 isolation level을 제공합니다.
1.READ UNCOMMITED
SELECT statements are performed in a nonlocking fashion, but a possible earlier version of a row might be used. Thus, using this isolation level, such reads are not consistent. This is also called a dirty read. Otherwise, this isolation level works like READ COMMITTED.
InnoDB가 제공하는 가장 낮은수준의 Isolation level으로 기본적으로 Read lock을 사용하지 않고 read를 수행합니다. 해당 수준에서는 다른 트랜잭션에서 commit 되지 않은 데이터를 read하여 dirty read가 발생 할 수 있습니다.
2.READ COMMITED
Each consistent read, even within the same transaction, sets and reads its own fresh snapshot.
For locking reads (SELECT with FOR UPDATE or LOCK IN SHARE MODE), UPDATE statements, and DELETE statements, InnoDB locks only index records, not the gaps before them, and thus permits the free insertion of new records next to locked records. Gap locking is only used for foreign-key constraint checking and duplicate-key checking.
매번의 read 마다 일관적 읽기를 통한 새로운 snap shot을 생성하며, read lock을 설정하지 않습니다.
명시적인 locking read를 사용시에는 gap lock을 설정하지 않고, record lock만 설정합니다. gap lock이 설정되지 않기때문에 phantom read가 발생 할 수 있습니다.
Consistent read (일관적 읽기)
Consistent read is the default mode in which InnoDB processes SELECT statements in READ COMMITTED and REPEATABLE READ isolation levels. A consistent read does not set any locks on the tables it accesses, and therefore other sessions are free to modify those tables at the same time a consistent read is being performed on the table.
READ COMMITED, REPEATABLE READ 모드에서 기본적으로 스냅샷을 이용한 일관된 읽기를 사용하며, 이를 통해 일반적인 read 에서는 lock을 걸지 않습니다.
다만, 특수한 상황에서 주의해야 할 사항으로 다음과같이 명시하고있습니다.
The type of read varies for selects in clauses like INSERT INTO … SELECT, UPDATE … (SELECT), and CREATE TABLE … SELECT that do not specify FOR UPDATE or LOCK IN SHARE MODE:
By default, InnoDB uses stronger locks and the SELECT part acts like READ COMMITTED, where each consistent read, even within the same transaction, sets and reads its own fresh snapshot.
INSERT INTO ... SELECT, UPDATE ... SELECT, CREATE TABLE ... SELECT 구문의경우 FOR UPDATE, IN SHARE MODE 보다 더 강력한 Lock이 걸리며 SELECT part의 경우 READ COMMITTED와 같이 매번 새로운 스냅샷이 생성됩니다.
3.REPEATABLE READ
This is the default isolation level for InnoDB. Consistent reads within the same transaction read the snapshot established by the first read.
InnoDB의 default isolation level으로, 스냅샷을 이용해 동일 트랜잭션 내 에서 일관된 읽기를 보장합니다.
This means that if you issue several plain (nonlocking) SELECT statements within the same transaction, these SELECT statements are consistent also with respect to each other
기본적으로 비잠금 read (Not For share, For update)의 경우 최초에 생성된 스냅샷을 이용해 일관된 읽기를 합니다.
또, READ COMMITED와 다른점으로는, 명시적인 locking read를 사용시에 next-key lock을 사용해 gap lock이 설정 됩니다.
4.SERIALIZABLE
This level is like REPEATABLE READ, but InnoDB implicitly converts all plain SELECT statements to SELECT … LOCK IN SHARE MODE if autocommit is disabled. If autocommit is enabled, the SELECT is its own transaction. It therefore is known to be read only and can be serialized if performed as a consistent (nonlocking) read and need not block for other transactions. (To force a plain SELECT to block if other transactions have modified the selected rows, disable autocommit.)
REAPEATABLE READ와 유사하지만, auto commit이 비활성화 된 경우 모든 Read에 대해서 S-Lock을 설정합니다.
원문 : https://dev.mysql.com/doc/refman/5.7/en/innodb-transaction-isolation-levels.html
Locks in special Condition
위에서도 잠시 부분언급했던 특수한 상황에서의 lock을 조금더 알아보도록 하겠습니다.
INSERT … ON DUPLICATE KEY UPDATE
INSERT … ON DUPLICATE KEY UPDATE differs from a simple INSERT in that an exclusive lock rather than a shared lock is placed on the row to be updated when a duplicate-key error occurs. An exclusive index-record lock is taken for a duplicate primary key value. An exclusive next-key lock is taken for a duplicate unique key value.
중복키에 대해 UPDATE를 실행하기에 당연한 내용이겠지만 INSERT ... ON DUPLICATE KEY UPDATE 구문의 경우, 일반적인 INSERT 구문에서 duplicate-key error가 발생할때 해당 record에 대해 S-Lock이 설정되는 것 과는 다르게 X-Lock이 설정됩니다.
INSERT INTO T SELECT … FROM S WHERE …
INSERT INTO T SELECT … FROM S WHERE … sets an exclusive index record lock (without a gap lock) on each row inserted into T. If the transaction isolation level is READ COMMITTED, or innodb_locks_unsafe_for_binlog is enabled and the transaction isolation level is not SERIALIZABLE, InnoDB does the search on S as a consistent read (no locks). Otherwise, InnoDB sets shared next-key locks on rows from S. InnoDB has to set locks in the latter case: During roll-forward recovery using a statement-based binary log, every SQL statement must be executed in exactly the same way it was done originally..
INSERT INTO T SELECT ... FROM S WHERE ... 사용시 SELECT Table (S)에 대한 lock 설정내용에 대해 주의해야합니다. READ COMMITED일 경우나 innodb_locks_unsafe_for_binlog = enable & !SERIALIZABLE 일 경우를 제외하고는 S table에 S-Lock이 설정되게 됩니다.
즉, default 설정인 innodb_locks_unsafe_for_binlog=disable & REPEATABLE READ level을 사용할 경우 S table에 S-Lock이 설정되게 됩니다.
위와 마찬가지로 CREATE TABLE ... SELECT ..., REPLACE INTO t SELECT ... FROM s WHERE ..., UPDATE t ... WHERE col IN (SELECT ... FROM s ...) 구문 모두 마찬가지로 s table에 S-lock이 설정됩니다.
FOREIGN KEY
If a FOREIGN KEY constraint is defined on a table, any insert, update, or delete that requires the constraint condition to be checked sets shared record-level locks on the records that it looks at to check the constraint. InnoDB also sets these locks in the case where the constraint fails.
외래키가 걸려있는 테이블의 경우 외래키 체크가 필요한 insert/update/delete에 대해서 S-Lock을 설정합니다.
REPEATABLE READ LOCK COMPETITION
위 Isolation level 별 Lock 정책을 알아본 내용을 바탕으로 REPEATABLE READ 에서 발생 할 수 있는 의도치 않은 Lock 경쟁(lock wait timeout, Dead lock)이 발생 할 수 있는 상황을 알아보도록 하겠습니다.
쉬운 설명을 위해서 예시테이블을 다시한번 이용해보겠습니다.
Table Name : a_table
pk id pw flag 10 taes abfbkjelg2l310eimkwo1 0 11 taesk 1jk1lr1lkwnef09u0wjjf9a 0 13 luke sdlvmoi1qwpqpw0qwjc 0 14 lukek avsdsavlkw1jio21io231f 0 20 luwak abfbkjefjk1jr23oijlklffj1 0
- pk_idx(pk)
- id_unq_idx(id)
Table name : a_dtl_table
pk name number age tel 10 김태성 1 21 010-0000-0000 11 김태성 2 29 010-0000-0000 13 루크 1 21 010-1111-0000 14 김루크 1 29 3 20 김루왁 1 33 010-0000-0000
- pk_idx(pk)
- name_number_unq_idx(name,number)
- name_age_idx(name,age)
Lock 경쟁 발생 가능 상황 1.
REPEATABLE READ에서 사용하는 NEXT-KEY LOCK으로 인해 생각치 않은 Lock wait가 발생할 가능성 있습니다.
#SESSION-1
DELETE FROM a_dtl_table
WHERE name = '김태성' AND age <= 21
#SESSION-2
DELETE FROM a_dtl_table
WHERE name = '김태성' AND age > 21
위 쿼리로 보면, 서로의 레코드에 전혀 영향을 주지 않을것 같지만 SESSION-2에서 NEXT-KEY LOCK을 사용하여 ‘name_number_unq_idx’의 ('김태성','1')의 레코드를 두고 Lock 경쟁을 하는것을 확인 할 수 있습니다.

예제에서는 db 처리량이 많지 않기때문에 문제 없이 순서대로 수행이 되겠지만, 실제 업무환경에서 데이터 처리량이 많을경우 Lock-wait timeout이 발생할 가능성도 있고 WHERE 조건이 돌고 돌아 데드락이 발생할 가능성도 있음을 인지 하여야 합니다.
이것을 피하기위해서는 유니크 인덱스 레코드를 개별적으로 찾을 수 있는 조건으로 쿼리 튜닝을 하거나 여의치 않을경우 transaction isolation 옵션을 해 Next-key lock을 사용하지 않도록 하는 방법이 있을것입니다.READ COMMITED로 설정
-> 위에서 READ COMMITED level 사용시 Gap-lock을 설정하지 않는다고 하였으나 Next-key Row에 대한 lock은 설정되는것으로 테스트 결과 확인됩니다.


‘name_number_unq_idx’의 ('김태성','1')의 레코드가 포함되지 않는 SESSION-2의 쿼리도 해당 레코드에 대한 lock을 걸고 있음을 확인하였습니다.
Lock 경쟁 발생 가능 상황 2.
이번 상황을 통해 REPEATABLE READ와 READ COMMITED의 차이에 대해서 좀더 알아보도록 하겠습니다.
#SESSION-1
DELETE FROM a_dtl_table
WHERE name = '김태성' AND age <= 21
#SESSION-2
INSERT INTO a_dtl_table(pk, name, number, age, tel)
VALUE(21, '김태성', 3, 29, '000-000-000')
REPEATABLE READ에서는, SESSION-1 DELETE Gap lock으로 인해 SESSION-2의 INSERT 작업에서 Lock 경쟁이 일어납니다.

실제로 작업내용을 확인해보면, ‘name_number_unq_idx’의 ('김태성','2')와 ('루크', '1')의 Gap 에서 Lock 경쟁이 일어나는것을 확인 할 수 있습니다.
이러한 Lock 경쟁으로 인해 대량의 Delete 및 Insert가 일어나는 배치작업의 경우 Lock wait timeout 및 데드락이 걸릴 수도 있는 상황이 벌어질수 있으니 주의하셔야 합니다.
해당 상황이 READ COMMITED에서 이루어졌다면 어떤 상황이 일어날까요. 위에서도 알아보았다시피 SESSION-1 DELETE에서 Gap lock이 일어나지 않아 SESSION-2 INSERT가 Lock 경쟁 없이 성공하게 됩니다.
Lock 경쟁 발생 가능 상황 3.
REPEATABLE READ의 consistent read는 일반적인 Select 에서는 lock을 걸지 않으나, 서브쿼리에서 select가 포함되게 될 경우 lock이 발생하게 됩니다.
이 lock의 발생 상황 고려하지 못했다면, lock 경쟁이 발생 할 수 있습니다.
#SESSION-1
DELETE FROM a_dtl_table
WHERE pk = 13;
#SESSION-2
UPDATE a_table
SET flag = 1
WHERE name in (SELECT name FROM a_dtl_table WHERE name like '루크');
#SESSION-1
DELETE FROM a_table
WHERE pk = 13;
해당 예제는 위 Locks in special Condition 중 UPDATE t ... WHERE col IN (SELECT ... FROM s ...)를 사용하면서 서브쿼리 타겟 테이블에 S-Lock이 걸려서 발생하는 데드락입니다.
S-Lock 발생 확인

결과 (데드락)
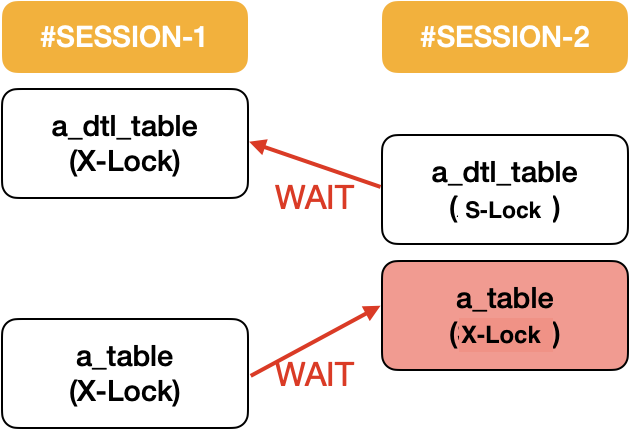
발생하기 정말 쉬운 데드락으로써, SESSION-1에서 a_dtl_table에 DELETE X-Lock을 잡고, SESION-2에서 a_table에 UPDATE X-Lock 그리고 a_dtl_table에 서브쿼르 SELECT S-Lock을 동시에 잡게됩니다.
이후, SESSION-1에서 a_table에 대해 X-Lock을 잡게되면서 다음과 같은 Lock-wait 순환이 일어나게 되어 데드락 상태에 빠지게됩니다.

REPEATABLE READ에서 일반적인 READ에서 lock을 걸지 않기때문에 놓치기 쉬운 부분일수 있습니다. 따라서 위에서도 살펴본 mysql에서 이야기 하고 있는 ` Locks in special Condition`을 사용할때는 사용자의 주의가 필요합니다.
Lock 경쟁 발생 가능 상황 4.
상황1과 거의 유사하지만, mysql 공식문서에서는 나오지 않은 특수한 케이스가 있습니다. 다음예제를 보시면 바로 어떤상황인지 이해가 되시리라 생각됩니다.
#SESSION-1
DELETE FROM a_dtl_table
WHERE pk = 13;
#SESSION-2
UPDATE a_table a
INNER JOIN a_dtl_table b
ON a.pk = b.pk
SET flag = 1
WHERE name like '루크';
#SESSION-1
DELETE FROM a_table
WHERE pk = 13;
상황1과 비슷하게, UPDATE JOIN 구문을 사용할시에도 join target이 되는 테이블에 S-Lock이 걸리게 됩니다.

Lock 경쟁 발생 가능 상황 5.
이번 케이스는 꽤나 흔하게 발생 가능한 상황입니다.
innoDB의 lock은 index record 및 gap에 걸린다고 위에서 정리를 했는데, 정확한 인덱스를 타지 못하는 쿼리를 작성시 엉뚱한 레코드에 락이 걸리는 상황이 발생 할 수 있습니다.
이번 케이스를 위한 별도의 예시 테이블을 생성해 보도록 하겠습니다.
Table Name : b_table
pk batch_seq id type type1 cnt 1 1 a 1 2 0 2 1 b 1 2 0 3 1 c 1 2 0 4 1 a 1 1 0 5 1 b 1 1 0 6 1 c 1 1 0 7 1 a 2 1 0 8 1 b 2 1 0 9 1 c 2 1 0 10 1 a 2 2 0 11 1 b 2 2 0 12 1 c 2 2 0 13 2 a 1 2 0 14 2 b 1 2 0 15 2 c 1 2 0 16 2 a 1 1 0 17 2 b 1 1 0 18 2 c 1 1 0 19 2 a 2 1 0 20 2 b 2 1 0 21 2 c 2 1 0 22 2 a 2 2 0 23 2 b 2 2 0 24 2 c 2 2 0
- pk_idx(pk)
- batch_seq_idx(batch_seq)
위 테이블은 배치성 테이블로, batch_seq, id, type, type1이 조합되어 유니크한 데이터를 만들어내는 예시테이블입니다. 위 테이블이 있다고 가정하고 쿼리를 실행시켜 보도록 하겠습니다.
#SESSION-1
UPDATE b_table
SET cnt = 7
WHERE batch_seq = 1
AND id = 'b'
AND type = 1
AND type2 = 2
#SESSION-2
UPDATE b_table
SET cnt = 7
WHERE batch_seq = 1
AND id = 'b'
AND type = 2
AND type2 = 1
위 쿼리를 보면, SESSION-1은 pk=2인 레코드, SESSION-2는 pk=8인 레코드를 수정함으로써 레코드 락은 물론이고 gap lock의 경쟁또한 없을듯하나 실제로 쿼리를 실행시켜보면 다음과 같습니다.

위 결과를 보면 우선 Lock이 잡혔습니다. 좀더 자세히 살펴보자면 PRIMARY index가 잡혔고, 상상치도 못하게도 pk=1 레코드에서 lock경쟁이 일어났습니다.
SESSION-2의 쿼리를 다음과같이 바꾸어도 똑같은 lock이 발생합니다.
#SESSION-2
UPDATE b_table
SET cnt = 7
WHERE batch_seq = 2
AND id = 'c'
AND type = 2
AND type2 = 2
실제로는 유니크한 값을 갖는 조건들 이지만, 해당 테이블에는 유니크임을 인지할수있는 인덱스가 없기때문에 lock이 어디에 걸릴지 예측하기는 쉽지 않을겁니다.
특히나 배치성 테이블의 경우 멀티 쓰레드로 같은 쿼리가 동작하면서 예상치 못한 lock 경쟁으로 인해 데드락이 일어날 수 있기에 더욱이 잘 고려해야 할 것 입니다.
이러한 lock경쟁을 피하기 위해서는 정확한 유니크 인덱스를 생성해 주던가, pk를 이용해 탈 수 있도록 쿼리를 작성해줘야 합니다.
마무리
서두에서도 이야기했듯이 InnoDB는 Lock을 이용하여 통하여 동시성과 일관성을 지키고 있기에 Lock 경쟁이 일어나는 것이 비정상적인 상황이아닙니다.
Lock 경쟁을 통해서 요청 쿼리를 일관성을 해치지 않으면서 순차적으로 처리해 줄 수 있기에 매우 자연스러운 상황입니다만, Lock이 어떤 상황에서 이루어지는지 모르고 데이터를 조작하게된다면 작업자도 모르는 상황의 오류가 발생 할 수 있기에 데이터를 조작하면서 Lock이 걸리는 케이스들에 대해서 잘 숙지 하시길 바라겠습니다.