Kafka
Apache Kafka is a community distributed event streaming platform capable of handling trillions of events a day. Initially conceived as a messaging queue, Kafka is based on an abstraction of a distributed commit log. Since being created and open sourced by LinkedIn in 2011, Kafka has quickly evolved from messaging queue to a full-fledged event streaming platform
간단하게 이야기해서, 카프카는 메세지 큐로 고안되어 현재는 다양한 이벤트 기반으로 처리 할 수 있는 ‘이벤트 스트리밍 플랫폼’ 입니다. 말은 조금 어렵지만 사용에 있어서는 일반적인 메세지 큐 라고 생각하고 사용이 가능합니다. 다만 카프카는 다른 MQ들과 비교하여 독자적인 특징들을 가지고 있습니다.
Kafka의 구성요소
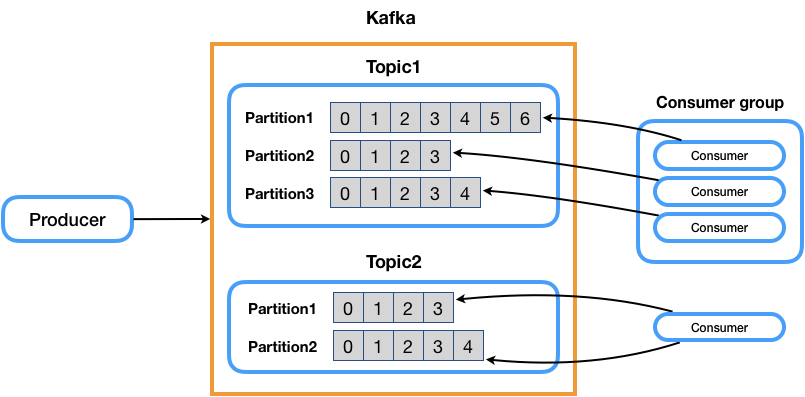
- producer : 메세지 제공자
- consumer : 메세지 소비자
- consumer group : 다중의 컨슈머들을 병렬로 처리하기위하여 컨슈머 그룹을 설정하여 각각의 다른 파티션으로부터 메세지를 읽어올 수 있습니다.
- topic : 카프카에 저장되는 메세지들은 ‘topic’이라는 메세지 ID로서 구분되어 저장되어집니다.
- partition : 메세지들은 병렬처리를 위해 topic 별로 분산 partition을 제공합니다.
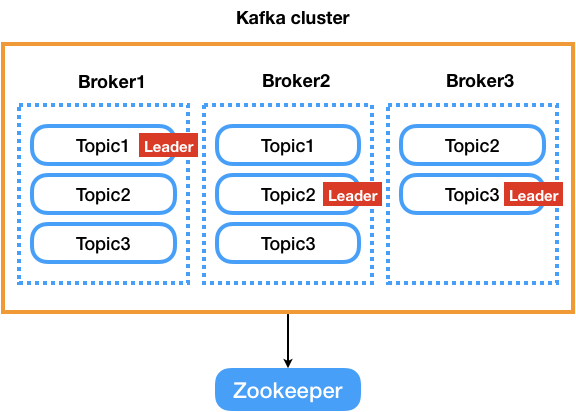
- kafka cluster : 카프카는 확장성(Scale out)/고가용성(HA)을 위하여 여러개의 브로커를 통해 클러스터링으로 구성되어 동작합니다.
- broker : 브로커는 카프카의 하나의 노드로써 메세지를 관리하는 주체가 됩니다.
-
zookeeper : Zookeeper는 카프카 클러스터를 관리하는 역할을 맡고있으며 produce, consumer 과정에서 카프카 브로커 및 오프셋 등 분산 처리환경을 관리하기때문에 카프카는 Zookeeper가 항상 함께 동작하여야 합니다.
Kafka의 특징
다른 MQ들이 많이 있지만 카프카가 개발자들에게 가장 큰 인기를 얻을수있는이유는 아마도 ‘고성능’ + ‘고가용성’ 이라고 할 수 있을것 같습니다.
카프카가 이러한 특성을 가질수 있는것은 다음과같은 카프카만의 특징때문입니다.
1. 고성능
카프카는 분산환경 특화 설계되어 다른 MQ들에 비해 고성능, 고안정성을 보장합니다.
- 다른 MQ들이 메모리에 데이터를 저장함에도 불구하고 카프카의 성능이 뛰어날수 있는것은 연속적 disk R/W와 함께 고효율적인 분산환경 처리를 진행하기 때문입니다.
- 또한 OS에서 제공하는 페이지캐시를 효과적으로 사용하여 disk I/O를 효과적으로 수행합니다.
- 분산환경으로 설계되어 스케일 아웃이 용이합니다.
- 배치처리를 통해 네트워크 Round trip을 줄여줍니다.
2. 고가용성
카프카는 데이터를 클러스터링을 통해 저장하여 장애에 대비 할 수 있도록 설계되어 있습니다.
- 분산환경 클러스터링으로, Single point of failure (단일 장애점) 문제에 대비가 가능합니다.
- 메세지를 파일 시스템으로 저장하여 휘발적이지 않습니다. (default 보관주기 : 7일)
3. 데이터 플랫폼
카프카는 ‘데이터 플랫폼’ 으로써의 역할을 할 수 있습니다.
예를 들어보자면 Kafka에 적재된 데이터를 로그분석 / 데이터 가공 / 빅데이터 처리 등의 각각의 엔드포인트와 연결하여 개별 소비가 가능합니다.
- 다른 MQ들은 한번의 consumption으로 데이터가 큐에서 제거되는것과 다르게, 카프카는 데이터를 유지하면서 consumer group마다 offset을 관리합니다.
- ‘플랫폼’이라는 말이 어울리게, 한번 저장된 데이터를 용도에따라 재소비가 가능합니다.