칼럼기반 Database
| 학번 | 이름 | 전화번호 |
|---|---|---|
| 101 | 김하나 | 010-1111-1111 |
| 102 | 이둘 | 010-2222-2222 |
| 103 | 석삼 | 010-3333-3333 |
위와같은 예제 데이터 테이블이 있다고 가정할때, Row base/ Column base DB가 각각 어떤식으로 데이터를 저장하는지 알아보도록 하겠습니다.
- 로우 기반 DB
data : “101;김하나;010-1111-1111,102;이둘;010-2222-2222;석삼;010-3333-3333”
위와같이 Row 단위로 데이터를 저장하게됩니다.
- 칼럼 기반 DB
data1 : “001:101,002:102, 003:103”
data2 : “001:김하나, 002:이둘, 003:석삼”
data3 : “001:010-1111-1111, 002:010-2222-2222, 003:010-3333-3333”
칼럼기반으로 데이터를 저장함으로써, 대용량 데이터에서 로우데이터 전체를 조회하는 로우기반 DB와는 다르게 특정 칼럼들만 조회하는데에 유리한 성능을 낼수 있는 구조로 만들기위해 설계되었습니다. 특히나 이와 같은 경우는 분석을위한 DB에서 자주 발생하기때문에 분석을 위한 데이터라면 해당 DB가 적합할수 있습니다.
칼럼기반 Database 종류
- SAP -> HANA
- IBM -> Netezza
- HP -> Vertica
- ORACLE -> Exadata
- AMAZONE -> Redshift,
- APACHE -> Cassandra, HBase
대부분의 칼럼DB는 상용으로 비교적 비싼 가격에 판매되고 있으며, 최근에는 무료로 제공중인 마리아DB도 칼럼베이스 Store engine을 제공하고있으나 아직은 이슈가 많아 안정적이지 못하다고 합니다.
칼럼기반 Database의 특징
- Write once 아키텍쳐 (Update하지 않음, insert & delete 트랜잭션처리)
- delete시 논리적삭제가 일어나고 주기적으로 물리적 삭제를 진행합니다.
- index가 없습니다.
- 기본적으로 테이블은 논리적인 개념으로 존재하고, 실제적으로 데이터가 저장되는 물리적 단위로는
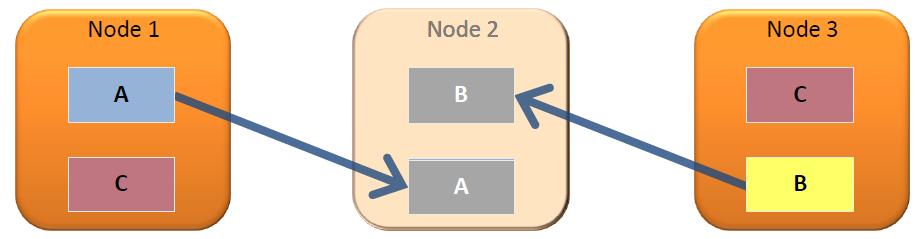
Projection을 통해 제공됩니다. - 클러스터구조 데이터 분산
Vertica 장점
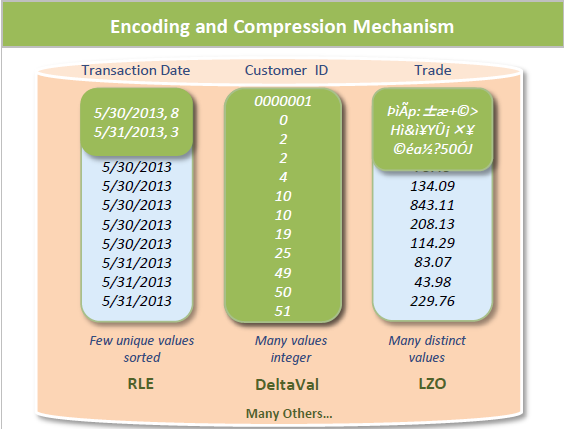
- 칼럼별 중복데이터에 대한 압축으로 디스크 점유공간을 크게 줄일수 있습니다.
- 중복데이터 뿐만 아니라, 데이터 자체의 압축알고리즘을 통해 데이터용량을 크게 줄입니다.
- 클러스터링 설정이 용이합니다.
- 칼럼별로 데이터가 저장되어 단일 칼럼 및 적은수의 칼럼데이터만들을 분석하는데 유리합니다.
- 특정 칼럼만 읽어서 갯수를 세거나 통계를 내는 분석용 데이터 베이스 작업에 유리합니다.
칼럼기반 Database의 단점 (↔ 로우기반 database)
- 여러 칼럼을 동시에 작업할때 불리합니다.
- 모든 칼럼의 값을 동시에 입력해야할때 불리합니다.