실행환경
- Python 3.7.3
- PyCharm
Crawler
크롤링이란 웹페이지를 불러와 데이터를 추출해내는 행위를 말한다.
이를 자동으로 해주는 프로그램인 간단한 크롤러를 만드는 예제를 만들어 보고자 한다.
크롤러 만들기
- http request 를 사용하기 위해 파이썬 requests 라이브러리를 이용한다.
pip install requests으로 간단하게 설치 가능하다.
크롤링 대상 사이트는 이 블로그사이트를 크롤링하는것으로 만들어 보도록 하겠다.
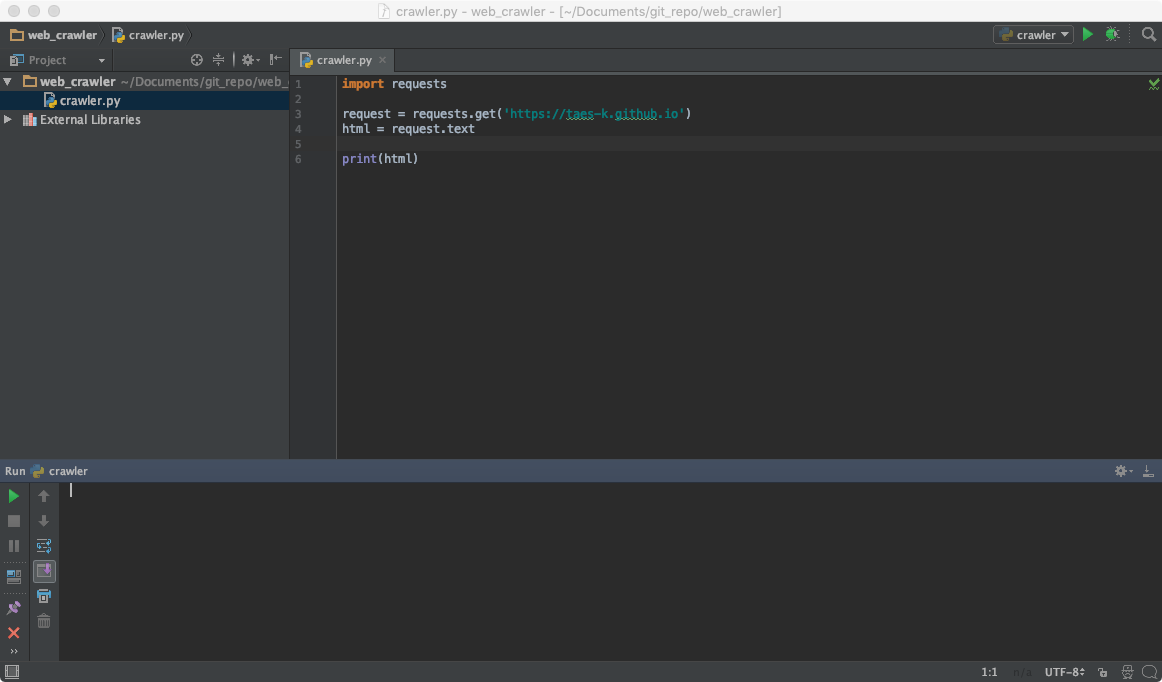
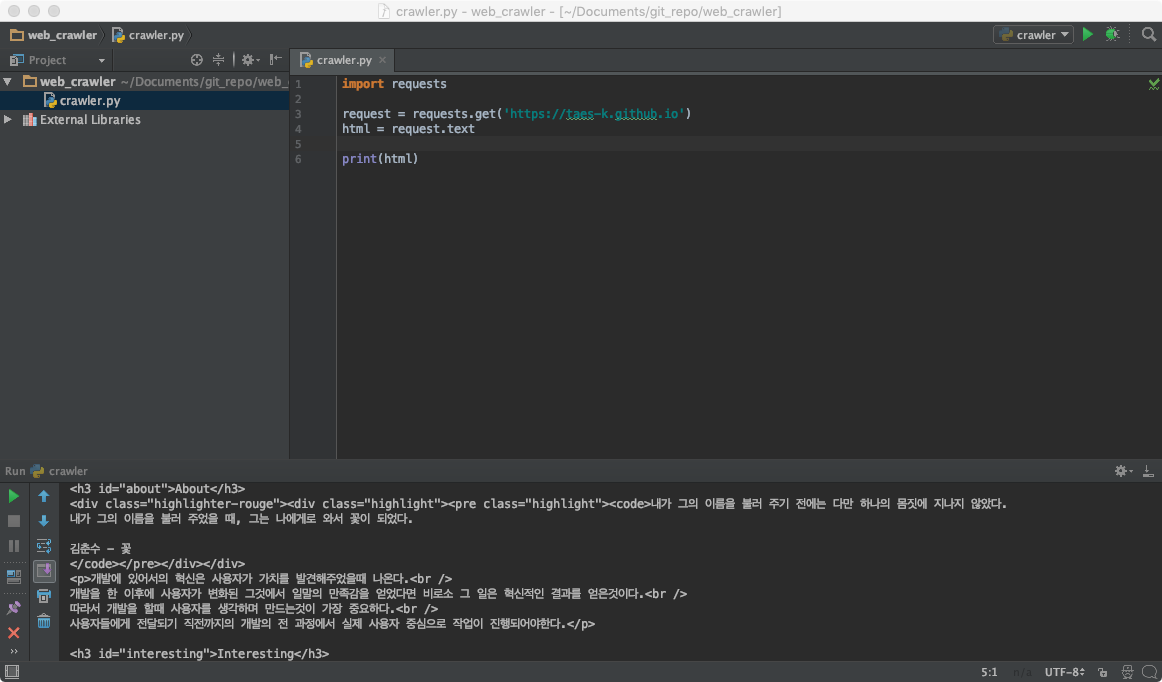
이 세줄짜리 코드로 벌써 웹페이지를 불러오는 과정이 끝났다.
- BeautifulSoup 라이브러리를 통해 html 을 정리하자.
BeautifulSoup 은 웹 크롤링 혹은 스크래핑을 할때 사용하는 파이썬 라이브러리로써 html소스를 보기좋게 trim 해주거나 원하는 내용만 필터링 하는등의 기능을 제공해준다.
pip install bs4설치
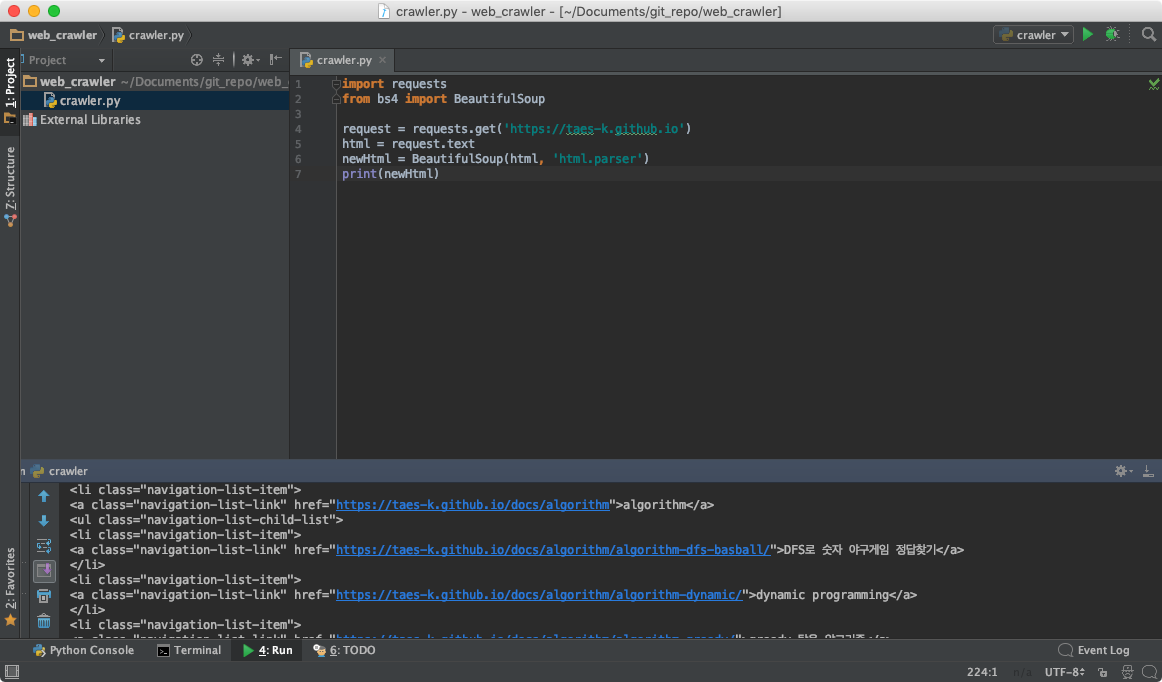 html 소스가 trim 되어 예쁘게 보여지는것을 확인할수 있다.
html 소스가 trim 되어 예쁘게 보여지는것을 확인할수 있다.
- 원하는 내용 select하기
html소스중에서 이제 내가 원하는 내용만 확인해보도록 하자.
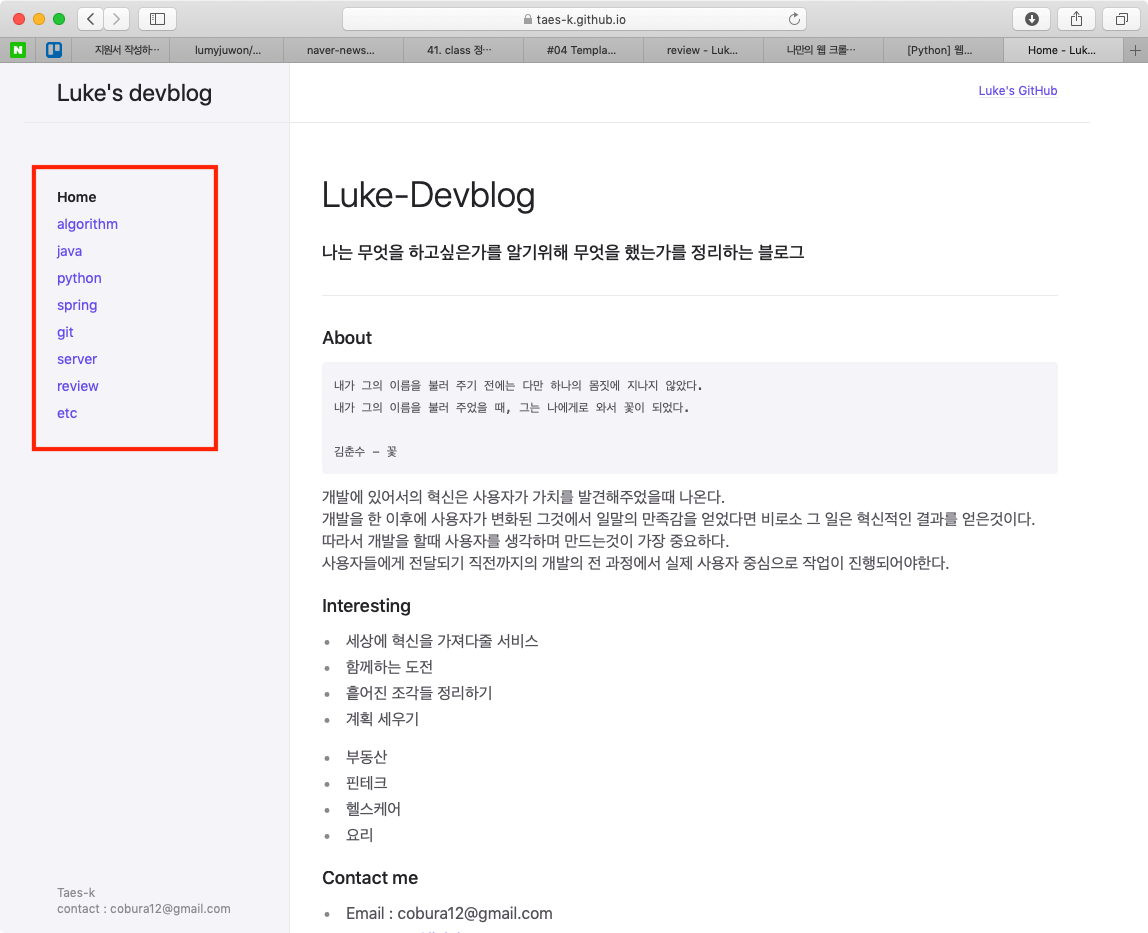 위 메인페이지에서 좌측 subject들만 가져오고자한다. 이때, BeautifulSoup의 select기능을 활용하면 손쉽게 확인이 가능하다. 이는, html 선택자를 기반으로 내용을 추출해올수 있다.
위 메인페이지에서 좌측 subject들만 가져오고자한다. 이때, BeautifulSoup의 select기능을 활용하면 손쉽게 확인이 가능하다. 이는, html 선택자를 기반으로 내용을 추출해올수 있다.
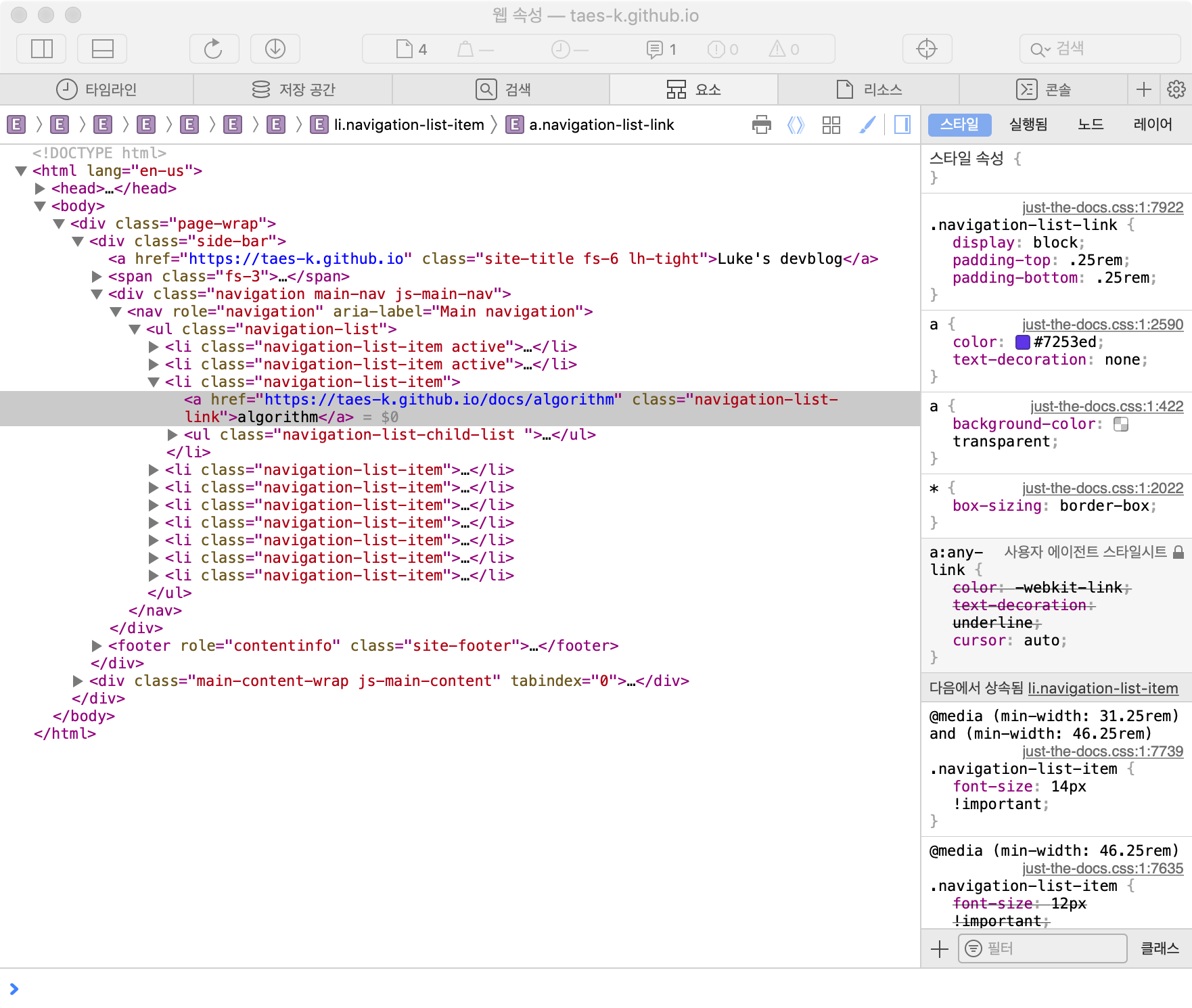
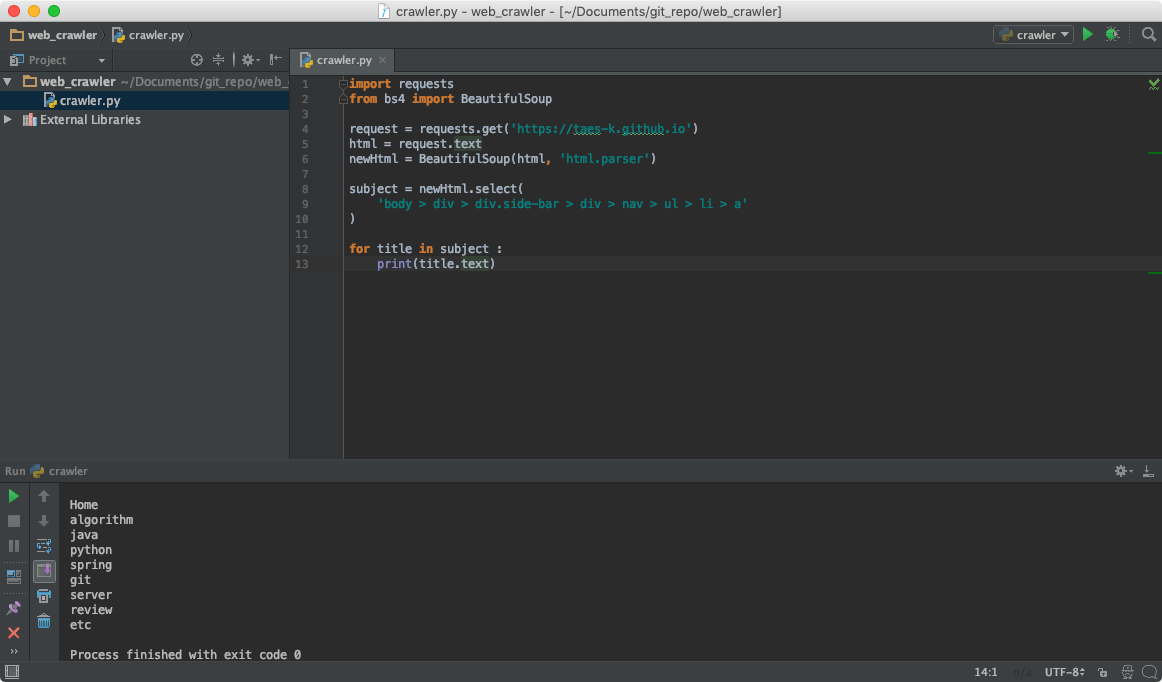
이로써, 원하던 subject title만을 추출을 완료하였다.
예제보기 : github https://github.com/taes-k/python-example/tree/master/web_crawler